LLMs for Knowledge Graph 1: Text to a Knowledge Graph at Warp Speed
· 17 min read
Welcome to our LLMs and Knowledge Graphs Series. In this collection of blogs, we embark on a journey at the intersection of cutting-edge large language models and graph-based intelligence. Whether you’re a seasoned data scientist, a curious developer, or a business leader seeking actionable insights, this series promises to demystify the synergy between LLMs and knowledge graphs.
What to Expect
Each blog in this series delves into practical applications, challenges, and opportunities arising from the fusion of LLMs and graph technology. From transforming unstructured text into structured knowledge, to prompt engineering and to unraveling complex relationships, we explore how these powerful tools can revolutionise information extraction and decision-making.
Let’s learn how to transform mountains of unstructured data into actionable insights with minimal effort, thanks to LLMs and GraphAware Hume.
Have you ever dreamed of producing a Knowledge Graph (KG) from a pile of textual documents at the click of a button?
A year ago, this would still sound like a loony’s dream. But today, we live in a different world. Almost everyone, not just data scientists knows of the formidable capabilities of Large Language Models (LLMs) in general and OpenAI’s GPT - the market leader - in particular. Although we can debate whether to call it “AI” or not, the bottom line is that these models enable anyone, not just data scientists, to do previously unthinkable things. With minimal technical knowledge and customisation, anyone can use it to answer various questions, translate documents, write an engaging article, generate code or images based on textual description … and many more.
At GraphAware, we have a long history of working with clients from diverse domains to produce KGs from their data sources. The unstructured data was always a challenge - definitely a super interesting one, but also an expensive one. That’s because training custom traditional Natural Language Processing (NLP) models for specific tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE) - the bare essentials for creating semantically relevant complex KGs - requires many months of specialised human labour needed to prepare good quality training datasets, followed by a need for expert data science & engineering skills to be able to train, fine-tune, deploy and maintain the respective ML models. And you typically need a whole pipeline of these models: NER, Coreference Resolution, RE, Entity Resolution & Disambiguation, etc.
The onset of the LLM era is rewriting this story from scratch. If we can converse with ChatGPT almost like with any other human or ask it to produce an innovative essay, why couldn’t we use it to perform NLP tasks such as NER and RE?
Even more - shouldn’t it be possible to do this without spending months of expert human labour, whether on prompt engineering or fine-tuning the models to our domain? This is a very interesting question. From the number of blog posts out there that looked into this topic and demoed it on a couple of pages of text, it would seem that nothing is easier than that. But is that really so? Would that work in production? What is the accuracy of this approach compared to traditional ML? And what about privacy and security? These are just some of the questions we shall address in our blog post series, of which this is the first one.
Today, let’s explore the first question: can we produce a meaningful, reliable, accurate KG from any set of documents from any domain using a simple generic prompt, with minimal to no domain expert intervention, i.e. at a click of a button?
Knowledge Graph at a click of a button
In order to achieve this task, we need certain basic ingredients:
- Data ingestion pipeline
- GPT-processing pipeline leveraging generic NER and relation Extraction prompt to accommodate data from any domain
- Post-processing pipeline
- GPT output parsing & validation
- configure user-friendly entity and relation validation & normalisation system
- automated graph modelling and schema definition (we don’t know up-front which entities and relations we’ll get)
- automated storage according to the KG schema
- KG visualisation and analytics
All of these can be obviously created once and reused for any future KG project. For example, using GraphAware Hume, two pre-canned Hume Orchestra (low-code data orchestration component in Hume) workflows are available to execute these steps on any dataset, and Hume Visualisation provides out-of-the-box graph-native exploration and analytics.
Let’s run a quick test to see how far we get with this “KG at a click of a button” approach. For this purpose, we shall investigate the famous case of state capture in South Africa, known as the Gupta Leaks. This is a case of systemic political corruption where business interests influence the state’s decision-making processes to their own advantage. Think of attempts to influence lawmakers or nominations of “friendly” people to state-owned companies or even ministerial posts. This use case is abundant in data sources: there are detailed investigative news articles, leaked emails and, most interestingly - detailed judicial proceedings, each typically of hundreds of pages worth of text. We shall only use one small judicial report in this blog post to demonstrate the concept: Report_Part_2_Vol_2.pdf_ (86 pages).
When it comes to the GPT prompt, we don’t have much choice - it needs to be very generic to accommodate any use case from any domain. We shall, therefore, ask GPT to “identify all named entities and relations among them” and provide them in JSON output format. This allows us to extract more complex patterns than just ENTITY - RELATION -> ENTITY. In the real world, each entity and edge can also have one or more additional properties. Think of complex money flows, where a company pays a certain amount to another company or person in order to buy their product or … their loyalty. We can therefore extract relationship Organization_1 -[:PAID_TO {amount: $8M}]-> Organization_2. Or consider a testimony of a person who talks about another person in the criminal investigation: we can identify not just that Person_1 - TALKED_ABOUT -> Person_2, but also a sentiment (did Person_1 talked about Person_2 in a positive or negative way?). Therefore, it is convenient to output JSONs with lists of entities (each entity having an integer unique ID assigned) and relations among them (where relations reference source and target entity by their ID).
It is also well known that a huge positive impact on explaining to GPT the task, i.e. ensuring higher prediction quality and stability, is providing an example. The tuning of the example is a typical task of prompt engineering, but remember: we want a generic prompt that will allow us to get a KG nearly at a single click of your mouse, with no customization! We, therefore, include just a random generic example, and we deliberately avoid using the above-mentioned TALKED_ABOUT and PAID_TO relations in order not to introduce positive bias in the later evaluation:
Example:
###prompt: "Mrs. Jane Austen, the Victorian era writer, is employed nowadays by Google as CEO. She was appointed in 2002."
###output:
{"entities":{"person":[{"id":0,"name":"Jane Austin","titles":["Mrs.","writer","CEO"]}],
"historical period":[{"id":1,"name":"Victorian era"}],
"organization":[{"id":2,"name":"Google"}]},
"relations":{"lived during":[{"source":0,"target":1}],
"works for":[{"source":0,"target":2,"title":"CEO","since":"2002"}]}}
Notice that although the example is very short, it encompasses the complexities of the output JSON format we expect GPT to produce: additional properties on (some) entities, such as list of titles of a person, and (some) relations, such as a title (CTO) on WORKS_FOR relations.
We’re almost ready to click “the button”, i.e. to execute the Hume Orchestra workflow, which has been pre-configured to ingest data, pass it through ChatGPT and generate a graph. Just one last thing remains, and that is the graph modelling, a.k.a. defining a graph schema. We shall opt for creating a metagraph layer made of the GPT entity mentions, i.e. nodes EntityMeta with label property holding the node class, and their relations, i.e. edges RELATED_TO_ENTITY with a type property holding the relation type. This layer represents an exact entity and relation mentions as they come from GPT, without any normalisation or any kind of postprocessing. This way, we can split the KG building task into multiple isolated logical sub-steps, making it easier to orchestrate the workflows and avoid the necessity to run GPT multiple times each time we change normalisation, resolution or other post-processing strategy.
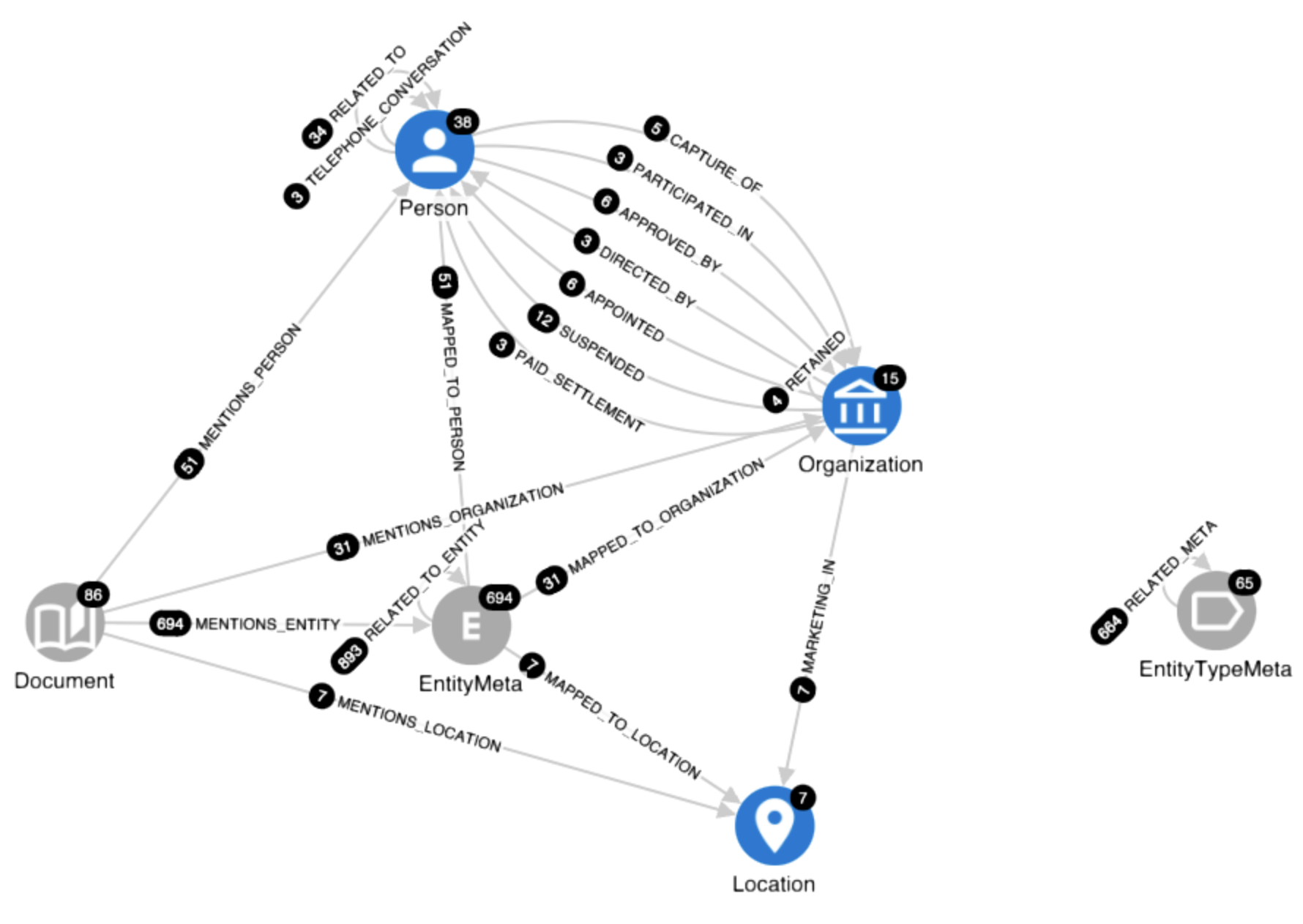
At the same time, we will also create a projected metagraph, a so-called meta-schema, representing not concrete entity and relation mentions but entity classes (EntityTypeMeta) and relation types (RELATED_META). We will see very soon why this choice. See the current schema in the figure below.
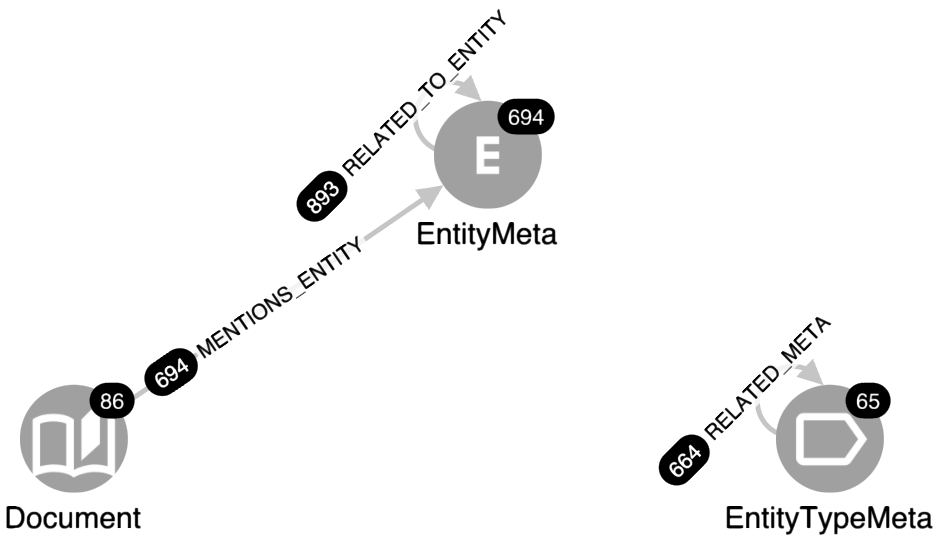
Now we’re ready to hit “the button”! The reward of our work so far is in the figure above - the schema view of our metagraph with counts of nodes and relationships (in black circles). We immediately see that within the 86 documents (pages), GPT identified 694 entity mentions and 893 relation types. Sounds like a pretty good outcome, right? However, look at the EntityTypeMeta part of the graph - to the 694 entity mentions, GPT assigned 65 different labels! Even worse - the 893 relation mentions were assigned 664 unique relation types! Now it should be clearer why we proposed in the list of ingredients above setting up a user-friendly entity and relation normalisation system (whose basis are the EntityTypeMeta nodes and RELATED_META edges) because GPT assigned to nearly every extracted relation a unique type different from other relations. If we created a KG right away, without any post-processing, it would already have, based on merely 86 pages of text, an extremely complicated schema with little usefulness for further downstream tasks - think about querying such a monster. Now imagine what would happen if we started processing thousands or even tens of thousands of pages! It should be obvious now why we decided first to create a metagraph layer.
Does it really work?
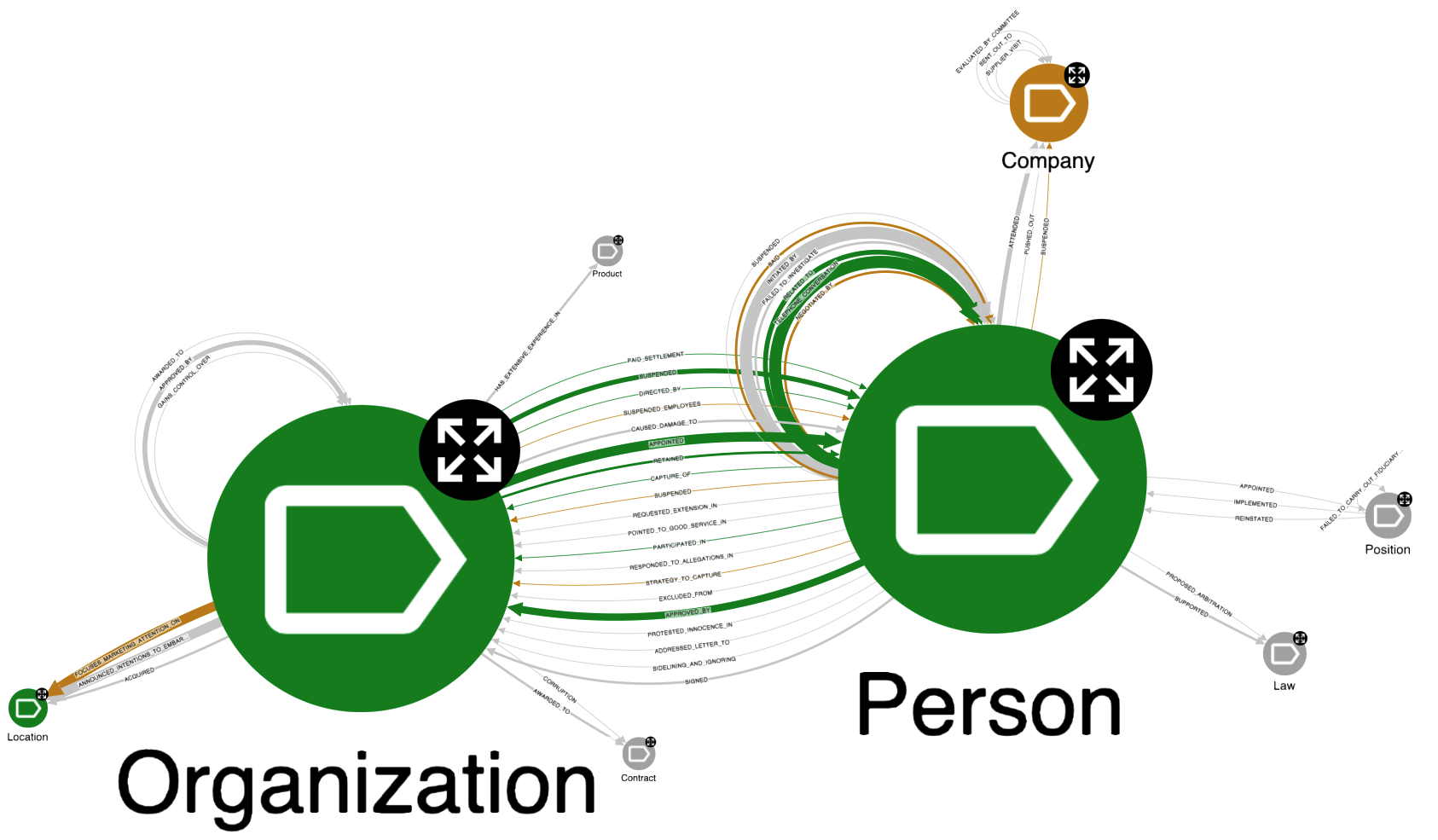
Let’s explore the meta-graph of entity labels and relation types. Expanding meta-schema (RELATED_META relationships), we’ll get a graph shown in the figure below. To avoid a hairball graph, we expanded only those relationships which were identified at least 3x. The styling of node sizes and relationship widths reflects how frequent the given node or relation is. Therefore, we immediately see that the most frequent entities are Person and Organization (perhaps not surprisingly since (a) this dataset is centred around uncovering criminal behaviour of organisations and people, (b) the prompt example contained these two entity classes), and among top relations we find for e.g. APPOINTED and TELEPHONE_CONVERSATION. Now it is time to investigate concrete examples: we use predefined local Hume Actions (pre-canned Cypher queries available as buttons in the UI) to show a table of top entity mentions (or top relations) of selected node class (relation type) along with the original text from which they were extracted.

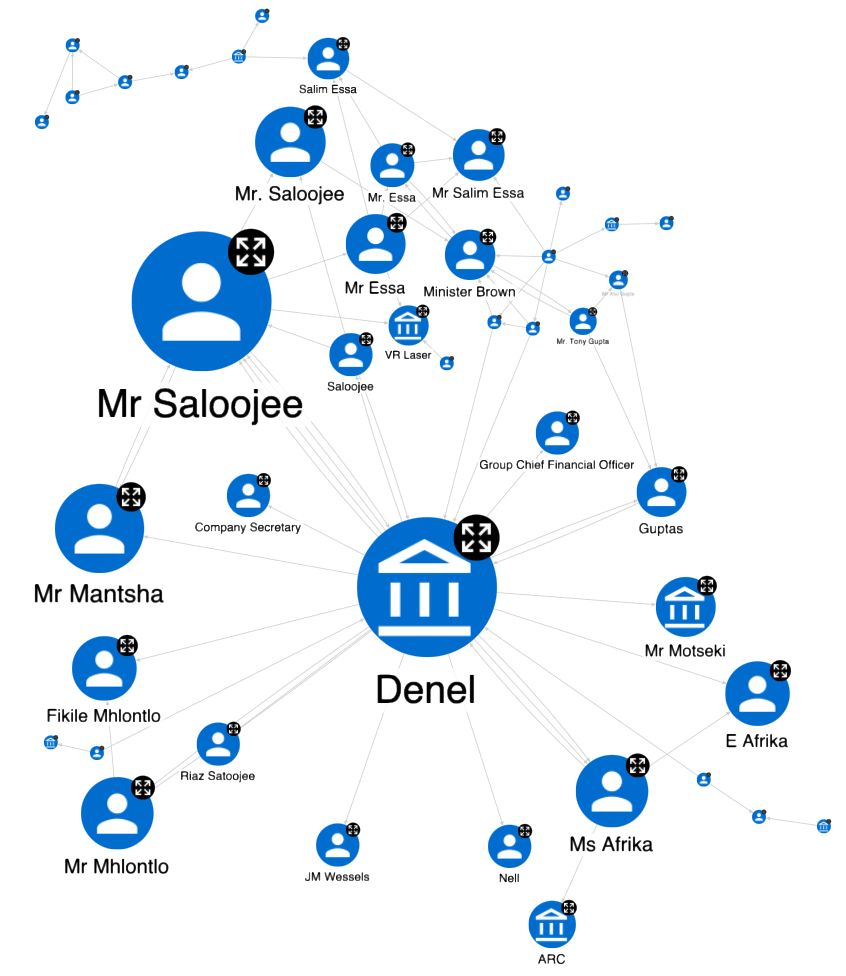
For example, triggering the local Action on the “Organization” node, we see a table where among top entity mentions, there are Denel, VR Laser or DLS - all well-known key players in the state capture case. When it comes to entity relations, we see:
- “Denel” - APPOINTED -> “JM Wessels” from text “Dr Nel had been the CEO of LMT at the time of its takeover by Denel. Dr Nel was kept on as CEO of LMT until he was replaced in March 2016 by Mr JM Wessels.”
- “Ms. Brown” - TELEPHONE_CONVERSATION -> “Mr. Salim Essa” from text “… and secondly, several telephone conversations between Ms Brown and Mr Salim Essa.“
ChatGPT (we used 3.5 turbo) was also successful in identifying some interesting relation properties, such as reason on SUSPENDED or date on SIGNED relations. These are obviously very promising results. Not bad for a generic prompt!
On the other hand, it is fair to point out the limitations of the domain-agnostic approach, for example:
- “Denel”
APPOINTED“Mr. Saloojee” from text “As will be shown, the retention of only one of the members of the Denel board appointed in 2011, the appointment in mid-2015 of a new board, the suspension of Mr Saloojee, Mr Mhlontlo and Ms Afrika in September 2015 all formed part of the Guptas’ strategy to capture Denel.” → In reality, Denel suspended Mr. Saloojee. - “Mr. Burger”
SIGNED“VR Laser” from the text “Five months after the DLS Single Source Contract with VR Laser had been signed by Mr Burger …” → depending on our preferred way of knowledge modelling, the relationships could be for e.g. “DLS”CONTRACTED“VR Laser” with edge propertiestype(“Single Source Contract”) andsigned by(“Mr. Burger”)
Finally, notice the normalisation issue: GPT produced node labels which are semantically very similar, almost identical, such as Organization and Company, and it did so even more in case of relations (664 of them from just 86 pages!), for example SUSPENDED vs SUSPENDED_EMPLOYEES vs SUSPENDED_EMPLOYEE vs NO_LONGER_AN_EMPLOYEE. It is obvious that with a generic (therefore ambiguous) prompt, the lack of clear guidelines on what entities and relations specifically are in our interest and how they are defined implies that the LLM is like a dog set loose during a walk - it will hop around from place to place, sometimes finding the right human-friendly direction, other times running through a random bush.
Knowledge Graph at few clicks
The unquestionable fact is that Large Language Models show great promise for Knowledge Graph building. On the other hand, they are not magic boxes that will solve all our problems right away. It is obvious now that the dream of producing an accurate domain-specific KG using an out-of-the-box model at the click of a button remains, for now, just that - a dream. However, we can get close enough. We will just need a few more clicks …
Without at least a few expert-level iterations on prompt engineering, we cannot overcome the failures discussed above, but we can design a system that will help us with the node & relation normalisation issue.
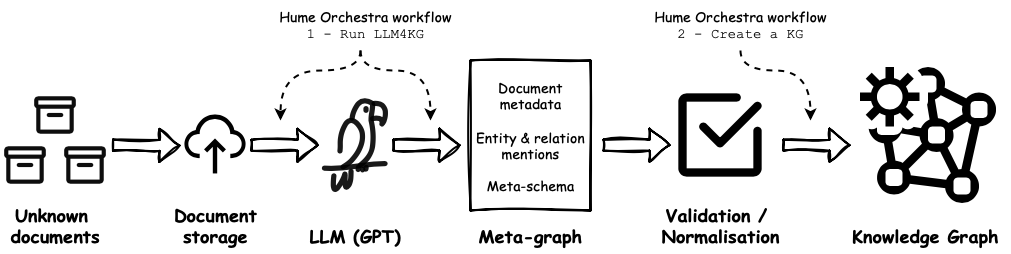
If you already are a GraphAware Hume user, the complex KG creation process described above is available to you with a few clicks, thanks to Hume Orchestra pre-canned workflows and Hume Visualisation. The steps for producing the meta-graph are as follows:
- Upload your data to your location of choice
- In Hume, create a new empty KG project
- Import & configure pre-canned LLM4KG workflows
- Run the first workflow, **
1 - Run LLM4KG, to produce a meta-graph
Following these steps, you will get out of the box (without any additional labour):
- Hume meta-KG schema created
- Hume Perspective, Styles and Useful Exploratory and Validation Actions created
- Deployment of ChatGPT with generic NER & RE prompt on your dataset, graph modelling and storage of the outputs in the Neo4j DB
- Simple user interface to validate and normalise the GPT entities and relations
Now we can start the normalisation process. Instead of expanding the full meta-schema graph (:EntityTypeMeta) -[:RELATED_META]-> (:EntityTypeMeta), we shall bring to the canvas only those relationships which are mentioned at least 3 times (showing all 664 edges would be difficult to handle) using Action MetaSchema - Show and choosing threshold 3 (see previous image). Of course, later on, we can move to less frequent relationships to continue the normalisation process. Now we explore the graph visualisation and start validating those relations that we want to have in the final KG layer:
- Use explainability local Actions on nodes or relationships, such as
MetaSchema - Relation examples w text. It shows the list of concrete relation mentions along with the texts so that we can understand what this edge represents and whether the relations are predominantly correct or not. - If the relation looks like something we’d like to have in the KG, we use Action
MetaSchema - Validate relation, which also allows us to rename the relation or entity classes if needed or even change the direction of the relation.
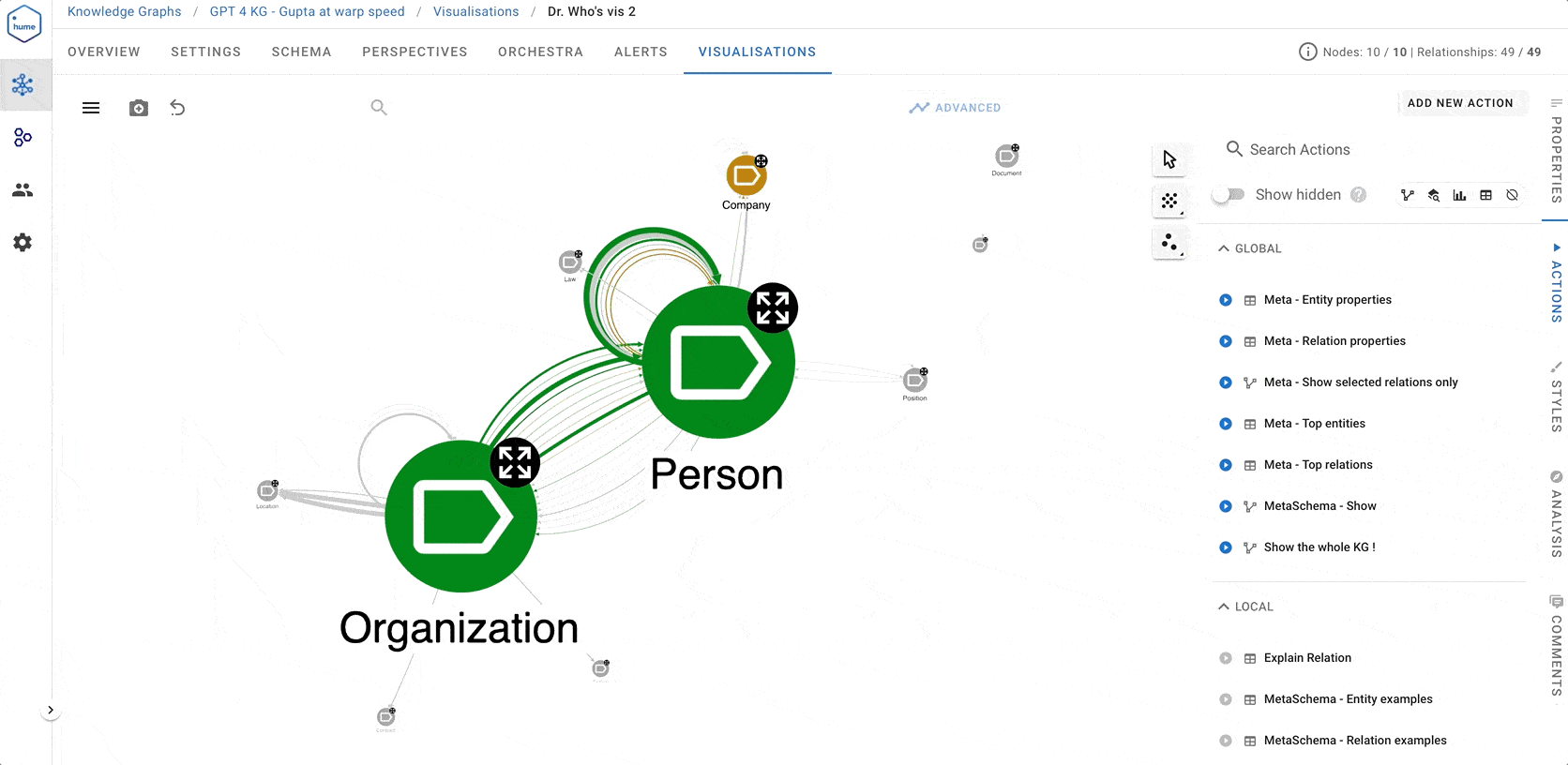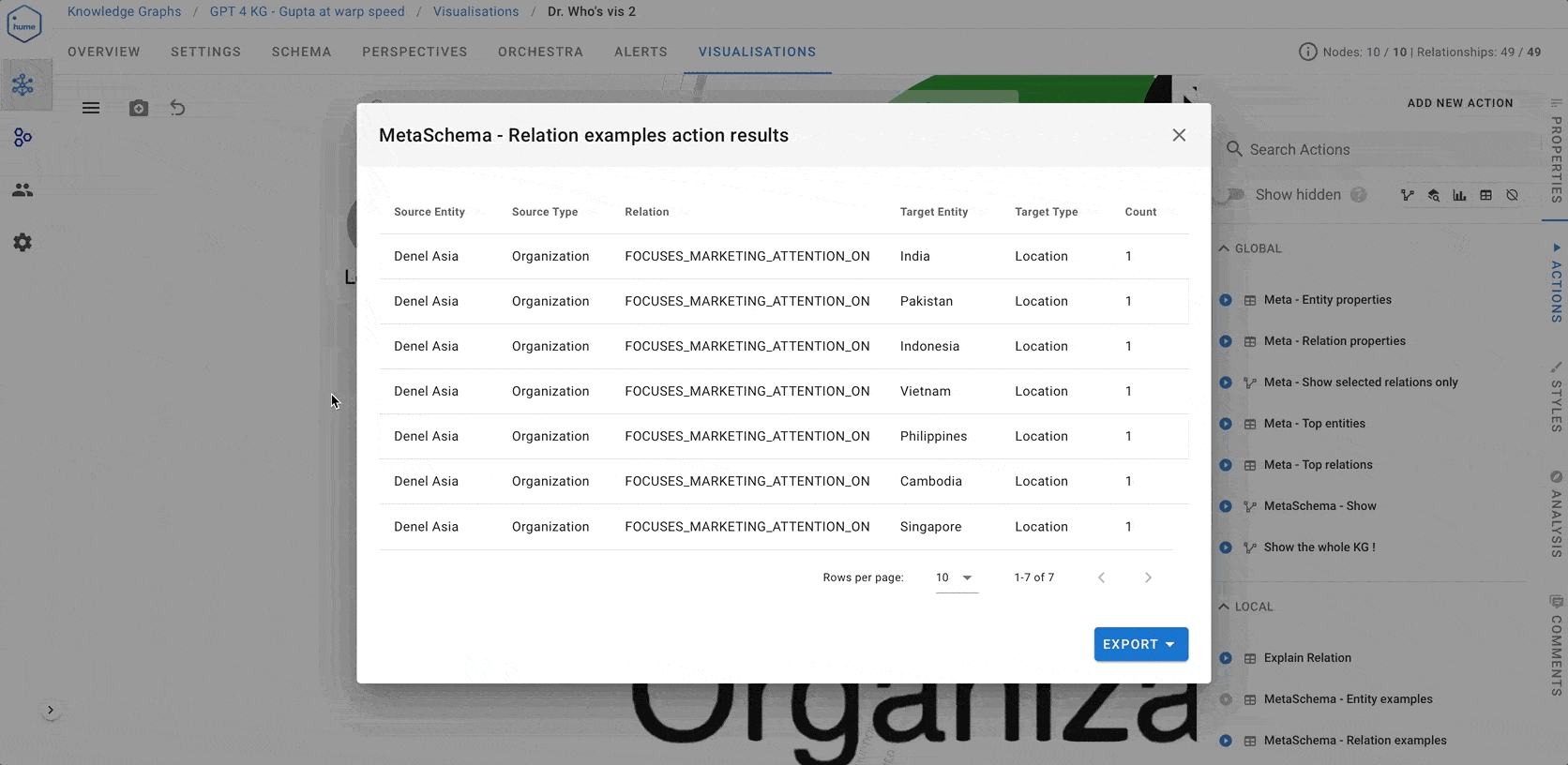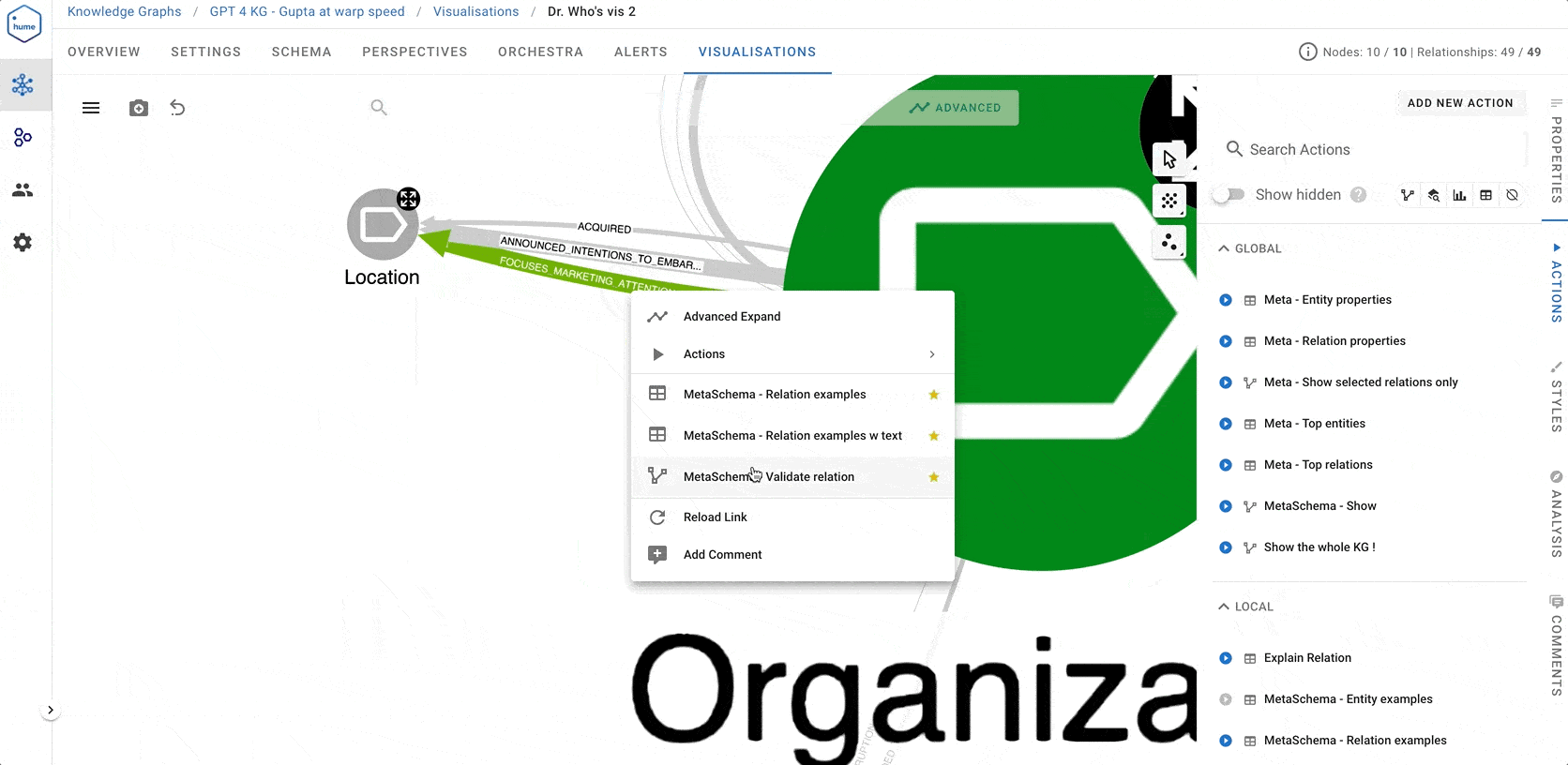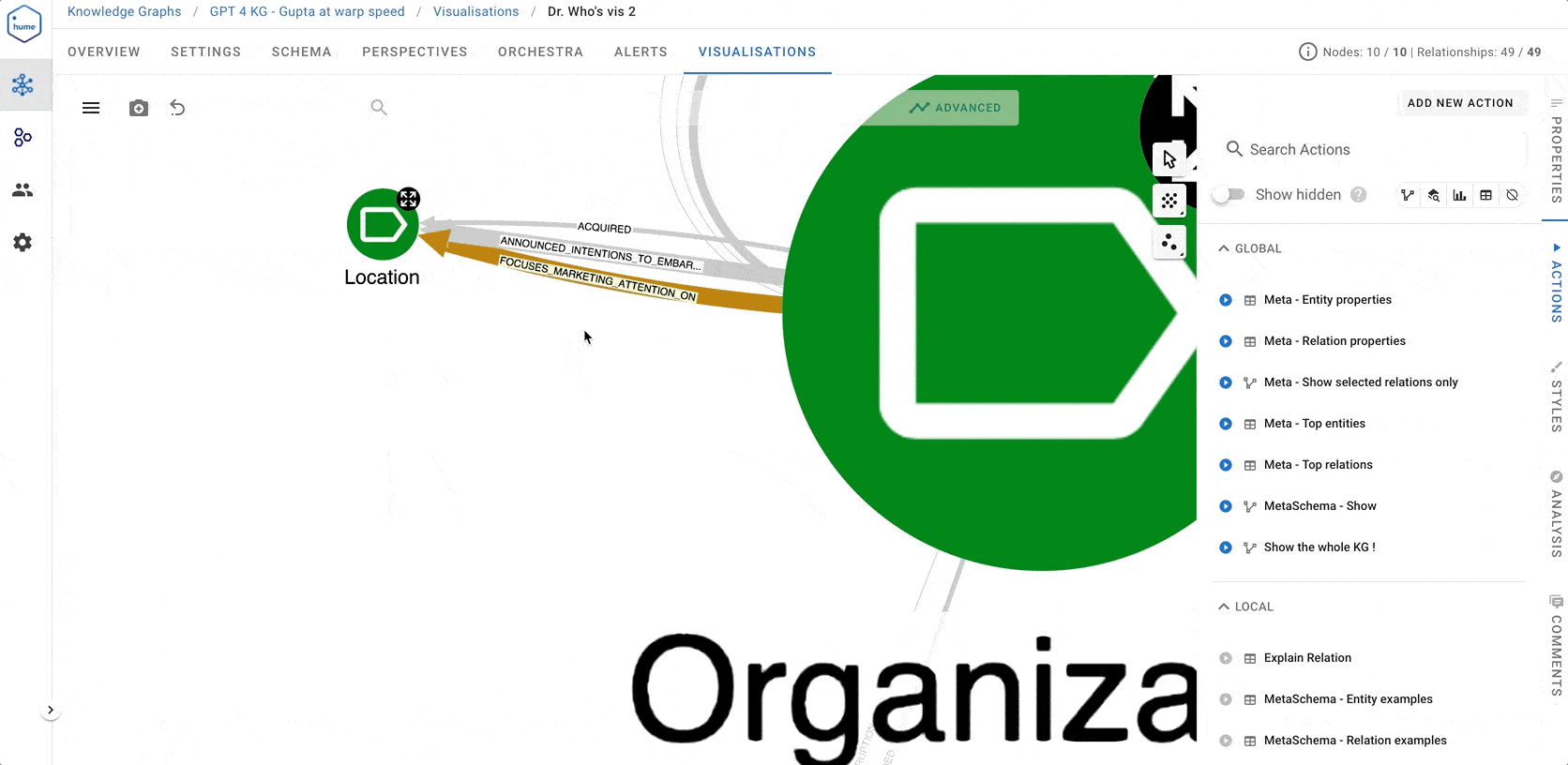
At the end of the normalisation process, we end up with a meta-schema looking something like the screenshot below. Several entity and relation classes are marked in green colour (keep them as they are) or orange colour (keep, but rename them).
From here, there is one last step towards the dreamt of Knowledge Graph - to run the workflow **2 - Create a KG. This will automatically, at a single click:
- Create final KG Hume schema (see figure below)
- Propagate meta-graph entity and relation mentions to the final KG layer
Oh, and by the way, we don’t have to go through all 664 relations; we can do it iteratively. Take a pause after going through a batch of relations, click the button to produce a KG, have a coffee while exploring and validating the fruits of your labour, and continue in the next iteration, if required.
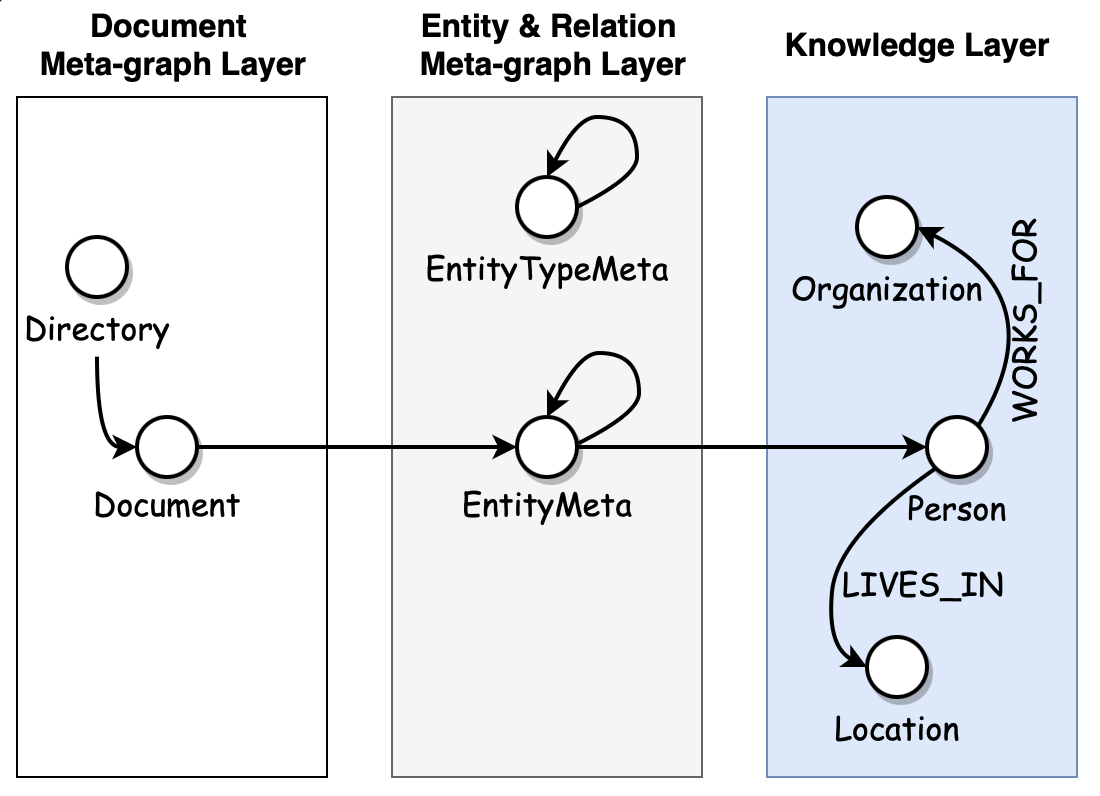
Designing the KG as a multi-layered onion (document layer, meta-graph layer, KG layer - see image above) has another advantage: we can configure the KG visualisation according to the needs of different personas. Frankly, final users don’t really care about the meta-graph; they just need to see and analyse the final normalised, fully cleansed and resolved layer. Sometimes, you don’t even want to see the Document nodes, only the relational knowledge within, just as it is shown in the screenshot below. This is an interaction network among people and organisations, styled according to the Eigenvector centrality graph algorithm. The bigger the node, the more central role it plays in this network. Not surprisingly, the KG reveals the key role of Denel defence conglomerate, captured by Guptas at the time, and Mr. Saloojee, one of former Denel’s chief executives.
What’s next?
In this blog post, we demonstrated the value and feasibility of building Knowledge Graphs from unstructured textual data using GraphAware Hume and LLMs with minimal initial effort. Steps to follow:
- Create a new Hume KG project
- Import and configure two predefined workflows
- Validate & normalise: run the
1 - Run LLM4KGworkflow and leverage click-through UI to validate and normalise entities and relations. - Produce the KG: run the
2 - Create a KGworkflow to produce the final KG
Though this “few click” solution is far from ideal in terms of knowledge extraction accuracy, it does have a huge potential.
Firstly, it can be used to answer the question, “What is in this pile of documents?” i.e. to produce a quick initial Proof of Concept-quality KG that anyone can do without any data science skills. They can then use the powerful Hume visualisation and graph algorithms to analyse it and draw initial approximate insights to assess the value.
Secondly, once the value is proven, this approach aids the prompt engineering phase (discussed in the following blog post). Remember the click-through validation process of the meta-schema? Well, performing this validation helps, at the same time, to get inspiration of what entities, relations, their properties and generally linguistic complexities should be covered when designing the optimal prompt. Ordinarily, we’d need to read through many pages to discover what specific knowledge we could mine from the documents, as well as to discover the linguistic challenges, so that our synthetic one-shot-learning example in the prompt prepares the LLM well for what is awaiting it in the dataset. Now, with this LLM4KG toolkit in place, the process is significantly streamlined.
This is the first blog post of our Large Language Models series, and it was not written by GPT!;-) In the next one, you will learn about prompt engineering for KG building and a proper analysis of the Gupta Leaks case!