Automated tests have become crucial in the field of software engineering in the last few years, even more than in the past. In fact, automated testing is now part of the Continuous Integration / Continuous Delivery (CI/CD) process, so tests may run in different shapes and environments throughout the development of software artefacts.While Unit Tests can be executed by taking apart a core component or class, by mocking every external dependency (DB included), Integration Tests and End-to-End tests require at least one real external component, in order to be as realistic as possible.
We are excited to announce a significant development in the field of graph-based analytics. We’ve teamed up with Neo4j to integrate their recently launched CDC (Change Data Capture) feature into our leading graph analytics tool, Hume. This partnership is transforming the landscape of graph technology, providing intelligence agencies and other organisations with powerful tools to unlock their mission-critical capabilities.
Only a few things are more satisfying for a graph data scientist than playing with Neo4j Graph Data Science library algorithms, most probably running them in production and at scale. Possibly also using them to fight against scammers and fraudsters that every day threatens your business.
When we started our journey with Neo4j over ten years ago, we were just a bunch of passionate techies trying to convince the world about the power of graphs. We were blogging, running meetups, writing open-source code, speaking at conferences, trying to preach graphs to a like-minded crowd.
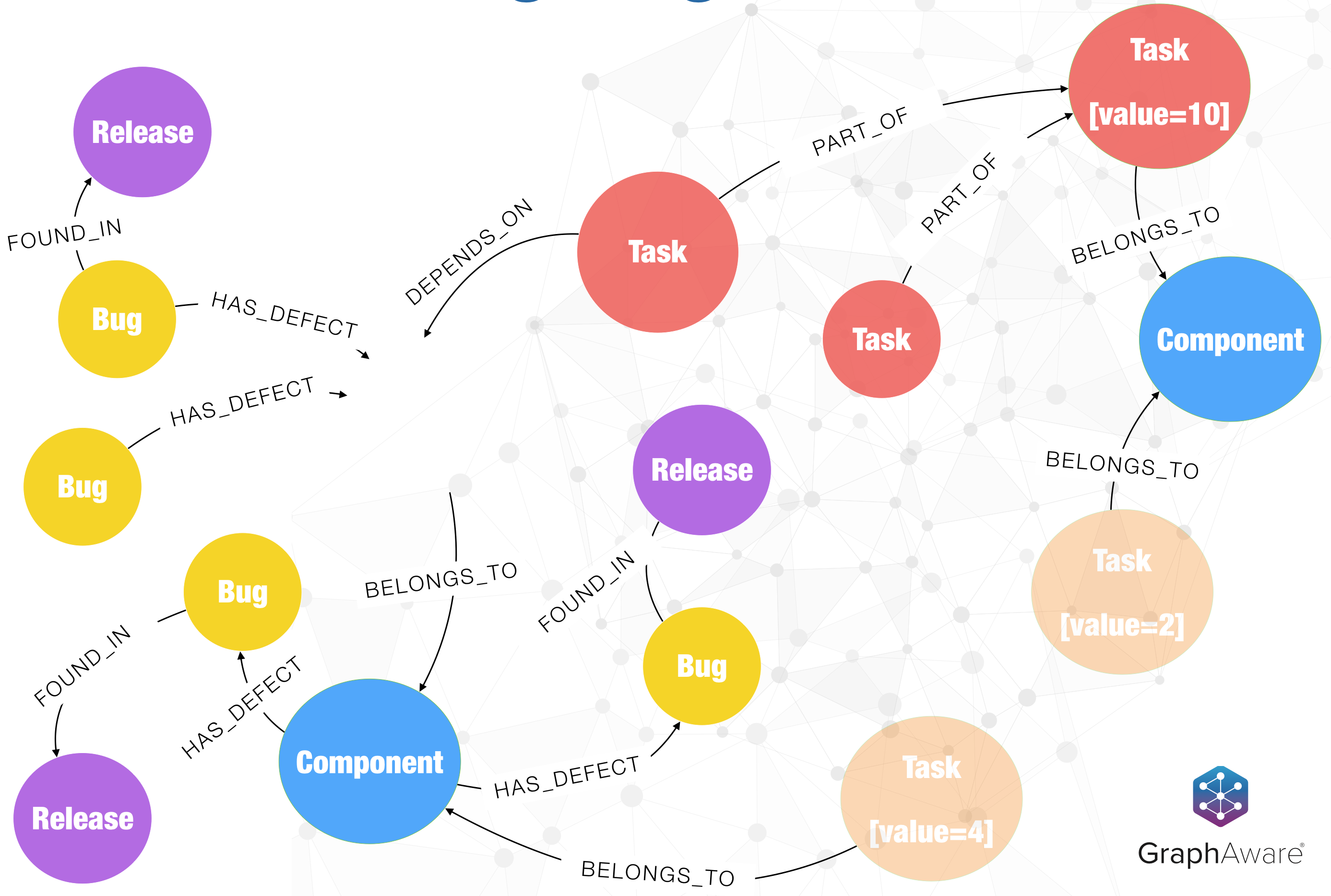
Say you have a graph-based project in mind. Be it research in life sciences, a fraud detection machine, or possibly a recommendation app. Anything that relies heavily on relationships between data points is a good case for a graph.
It has been over 8 years since I’ve written the first lines of code for the GraphAware Neo4j Framework as part of my MSc. thesis. That’s when the name GraphAware, as well as the (then) one-man show Neo4j consulting company was born. It is therefore my bittersweet duty to take you on a small trip down the memory laneand announce that we have decided to discontinue the development and support of the Framework and all of its modules.
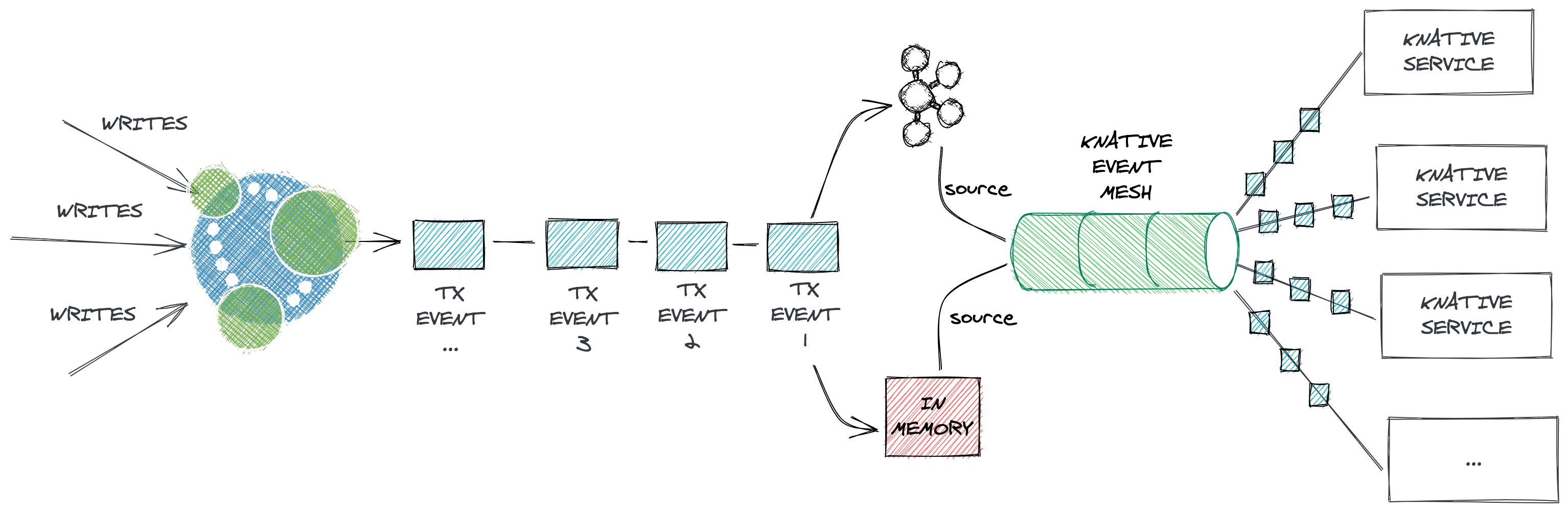
CDC (Change Data Capture) is a well defined software design pattern for a system that monitors and captures data changes so that other software can respond to those events.
Phonetic matching attempts to match words by pronunciation instead of spelling. Words are typically misspelled and exact matches result in them not being found.Algorithms such as Soundex and Metaphone were developed to address this problem and they have found usage in the areas of voice assistants, search, record linking and fraud detection, misspelled names of things (for example, medical records) etc.
The release of Neo4j 4.0 brought many improvements, one of them being areactive architecture across the stack, from query execution to clientdrivers. But how does that compare to other approaches ? As stated inthe reactive manifesto, areactive system is more scalable and responsive, by having a more efficient resource usage.
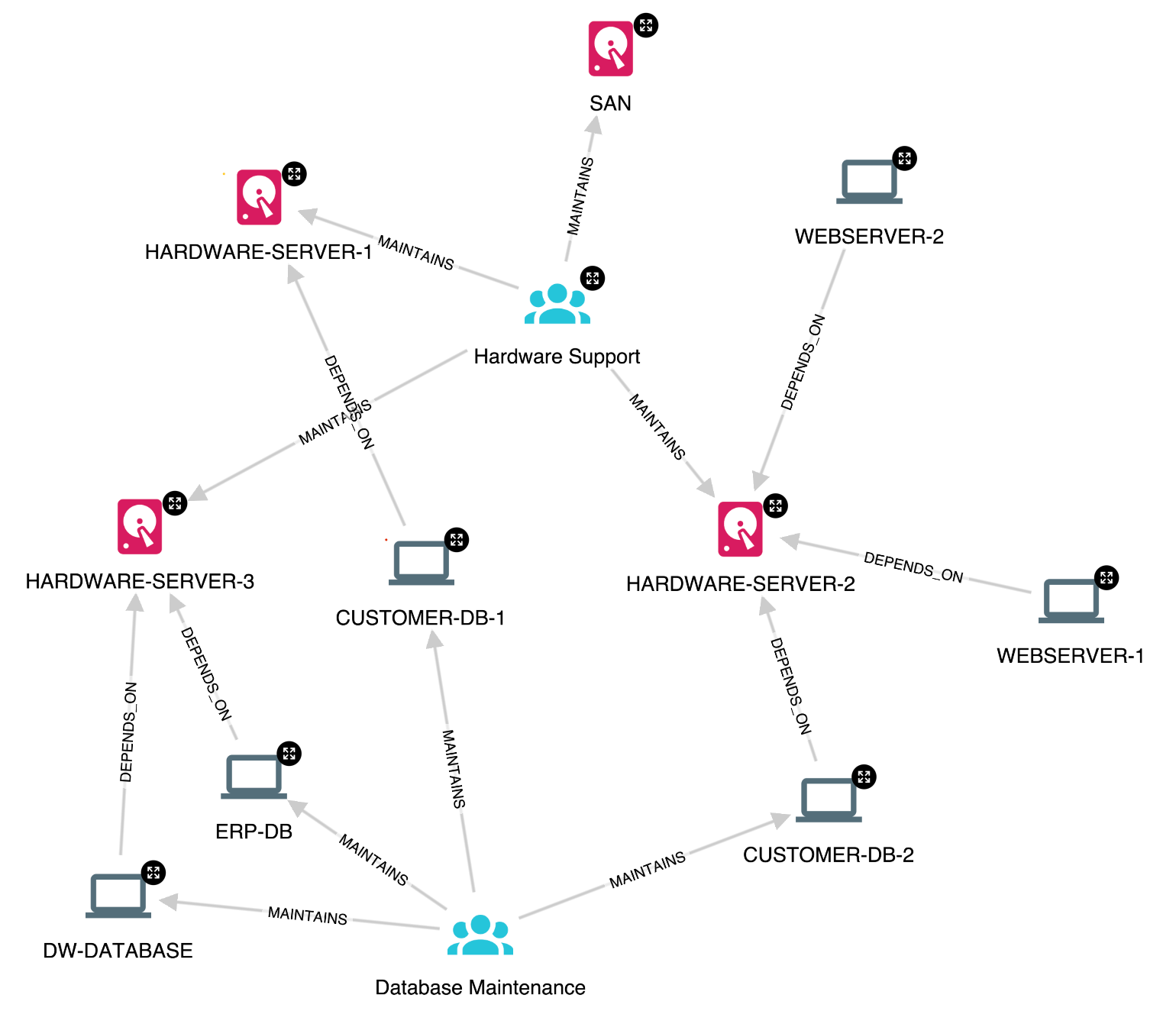
Graphs are a perfect fit for IT Operations. Right from dependency management to impact analysis and capacity to outage planning, the interconnectedness of the components that make up networks and services, modelled naturally as a graph enable various teams such as support, help desk and devops to navigate potentially complex relationships.
The GraphAware team is excited to release the neo4j-sso third-party security extension, compatible with Neo4j Enterprise, version 4.0 and above.
GraphTour Europe 2020 started in Amsterdam on February 4, right after the release of Neo4j 4.0, a key milestone in the graph technology landscape. At GraphAware we are very excited about the new features included in this release because they revolutionize the way we approach some common graph challenges. Our CEO, Michal Bachman spoke about this in Amsterdam in his talk “Practical Applications of Neo4j 4.0”, and he and other GraphAware experts continue to present in each of the six cities where we sponsor GraphTour. Find out what’s the next virtual event and register for free.
Neo4j has implemented very useful algorithms in order to derive insights from your graph data.
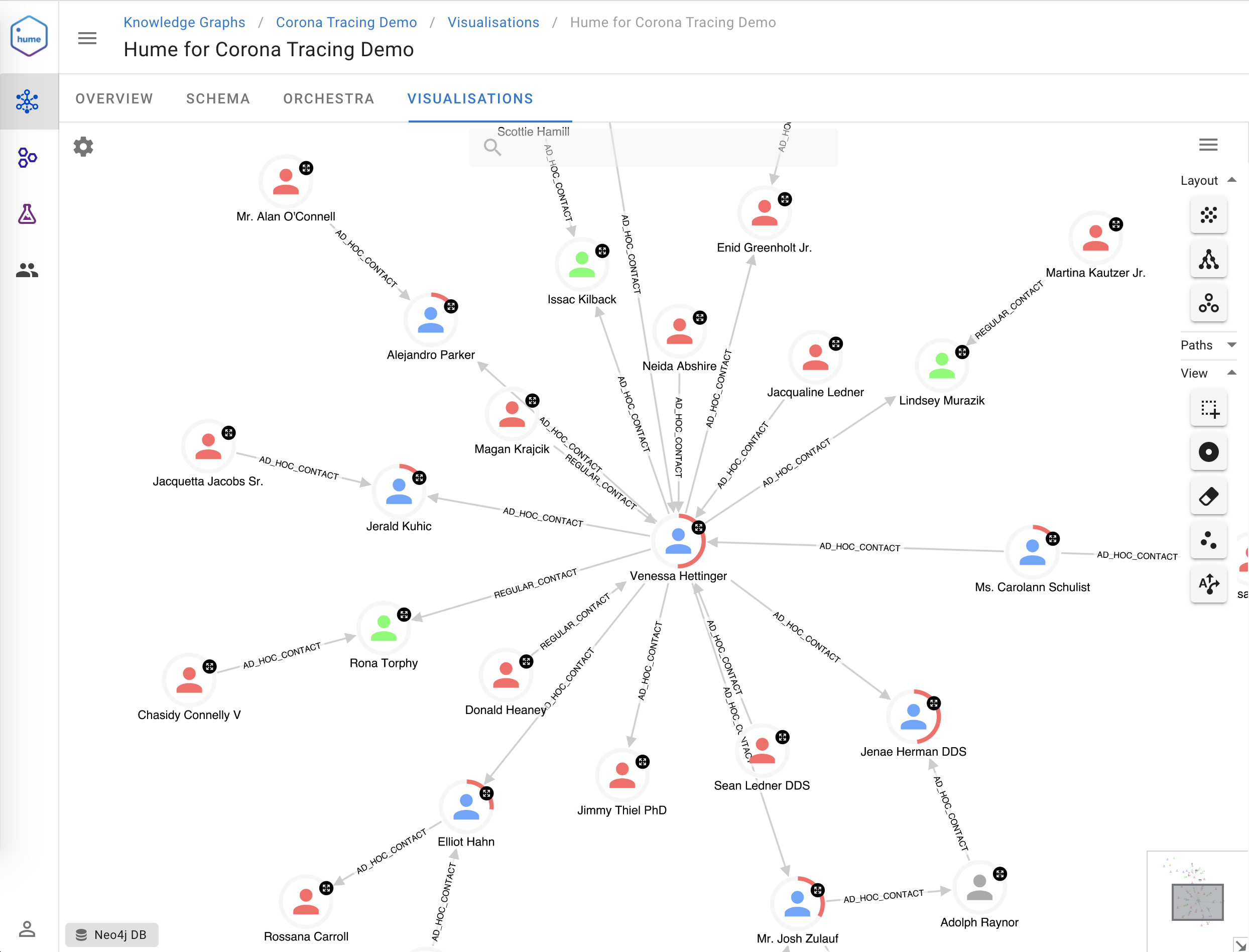
GraphAware Hume helps governments in keeping their countries safe. In this 15-minute video, we demonstrate the use of Hume for contact tracing and smart quarantine in the context of the current coronavirus pandemic. Specifically, we will see how Hume can identify people at risk using actual and potential contact tracing, suggest who should be informed or quarantined, visually explain why someone is at risk, find quarantine offenders, and much more.
Neo4j 4.0 has just been released with a key feature: graph and sub-graph access control. Access to certain labels or relationship types or properties can now be handled at the database level, resulting in developers not having to deal with complex security logic in their code, and also providing a more consistent and performant solution.
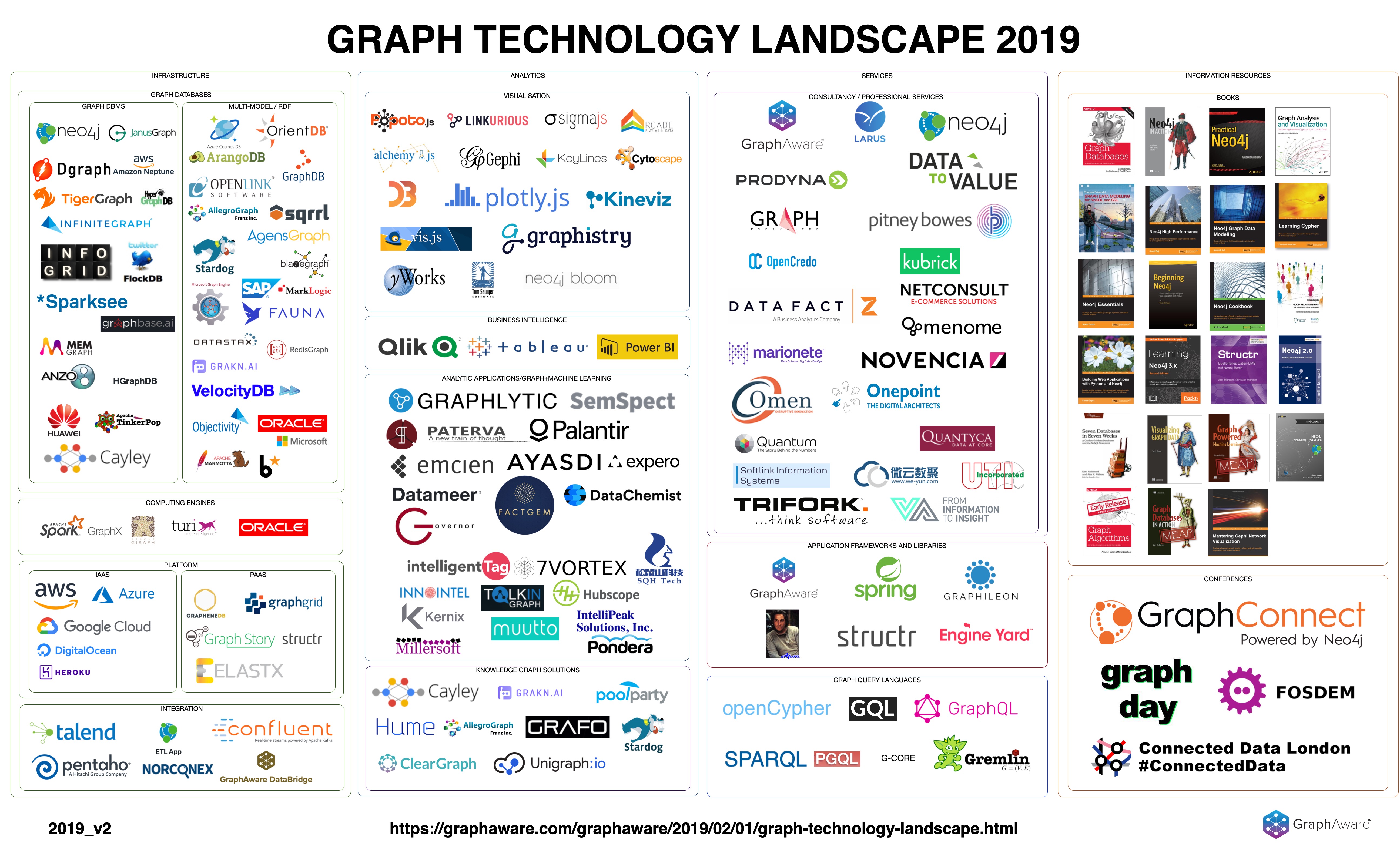
It’s been a year since I published the Graph Technology Landscape 2019 post on GraphAware’s blog. I consider this a success story because it got a lot of attention and publicity. The landscape was mentioned many times at different places; it was used by Emil Eifrem in his GraphTour and GraphConnect opening keynotes, it was displayed in conference halls, and I received many, many useful comments and feedback. I was even invited to Rik van Bruggen Graphistania Podcast to talk about it, and the episode was referred to in the Top 5 Neo4j Podcasts of 2019 blog posts as well....
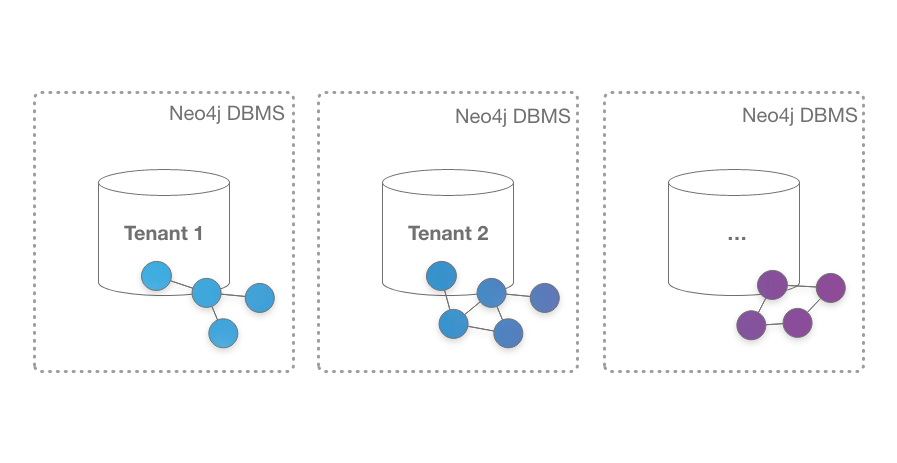
Up until version 4.0, Neo4j has supported only one active database per server instance. As such, achieving multi tenancy meant that either a Neo4j instance had to be deployed per tenant, or all tenant graphs co-existed in the same database.
Many, many years ago, I requested for the Cypher UNION clause in Cypher and Andres Taylor graciously added it.This was followed by the request for Post-Union Processing by Aseem Kishore, and it began to collect a whopping 99 comments over the course of time.
So you have followed the Deep Dive into Neo4j’s Full Text Search tutorial, learned even how to create custom analyzers and finally watched the Full Text Search tips and tricks talk at the Nodes19 online conference?
GRANDstack tips and tricksUsing GRANDstack can rapidly accelerate the development of applications. The neo4j-graphql-js library provides the ability to translate GraphQL queries from the frontend to Cypher queries. This is achieved by defining the GraphQL schema and annotating it with a few extra directives. If you want to get familiar with the GRANDstack you can visit their documentation.
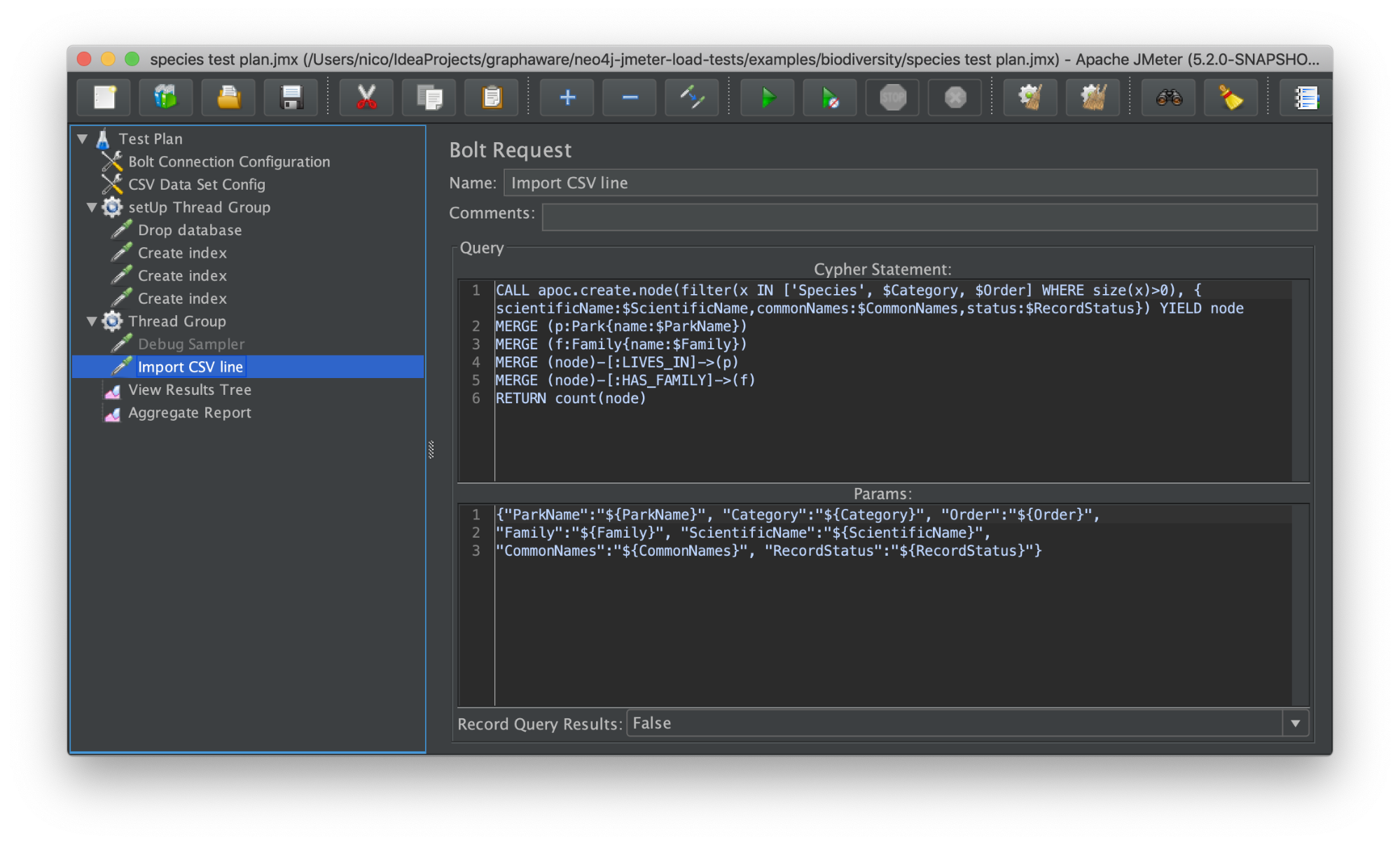
For the Global GraphHack 2019, we extended JMeter to support the Bolt protocol and do load testing on Cypher queries.
We have already blogged about fulltext search available in Neo4j 3.5. The list of available analyzers covers many languages and fits various use cases. However once you expose the search to real users they will start pointing out edge cases and complain about the search not being google-like.
The Cypher query planner is quite advanced and mature, and you can mostly rely on it to pick the best plan for your query. However, there are rare cases, or bugs, that might want you looking for ways to influence that plan. This article demonstrates practical usage of an index hint.
Neo4j Desktop, part of the Neo4j Graph Platform, is a client application that installs on your desktop OS. It lets you get started quickly by downloading and installing the enterprise edition, and supported plugins. You can group related graphs and applications under a Project. You can also build single-page web applications that run within Neo4j Desktop and have access to these services provided by Neo4j Desktop. There are a number of apps available at https://install.graphapp.io/
“Lateral thinking” was a big topic back in 2004 when I was in the Network Operations Center (NOC) business; one definition is:
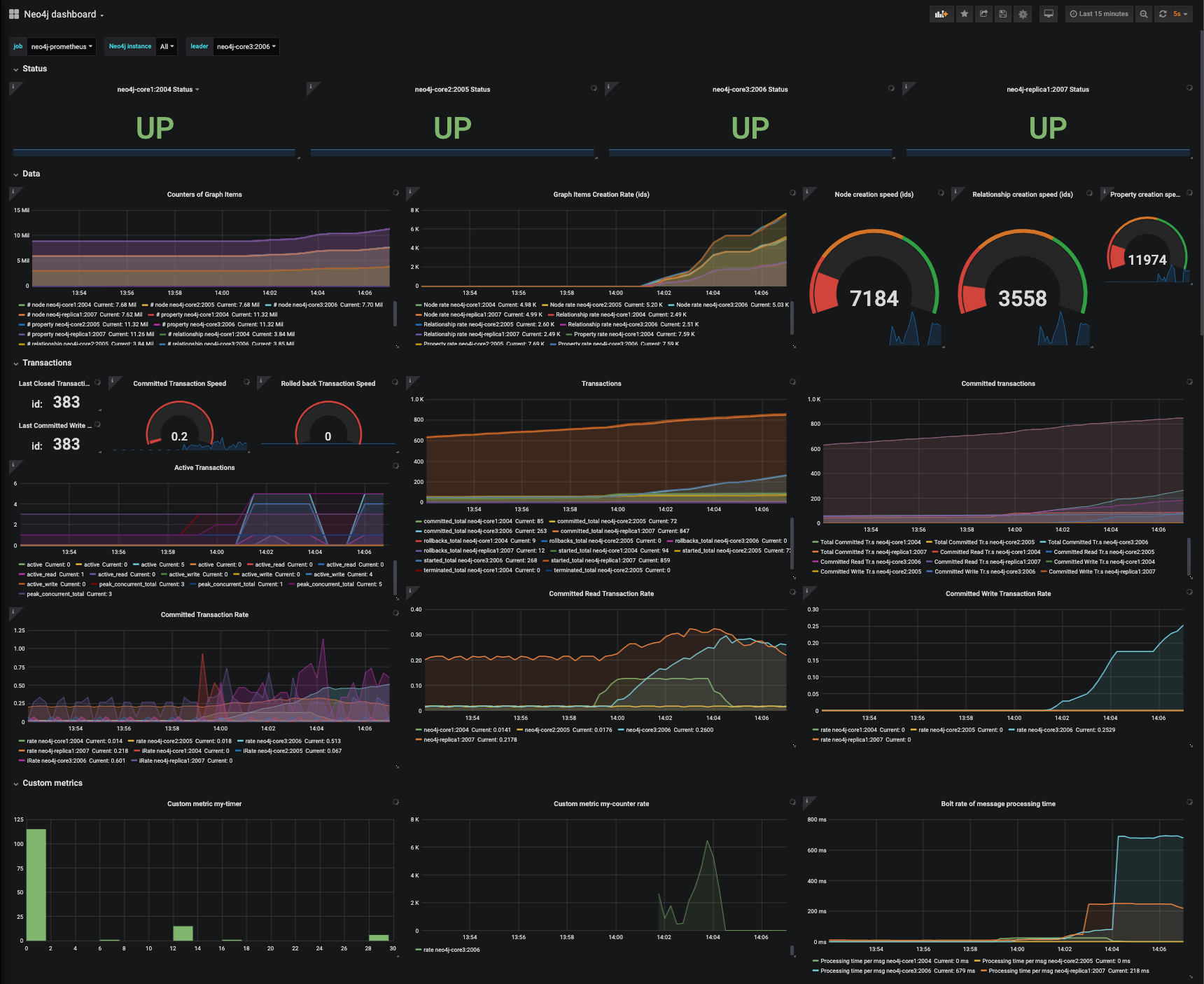
This is the second of a two post series on monitoring the Neo4j graph database with popular enterprise solutions such as Prometheus and Grafana. Monitoring the status and performance of connected data processes is a crucial aspect of deploying graph based applications. In Part 1 we have seen how to expose the graph database internals and custom metrics to Prometheus, where they are stored as multi-dimensional time series.
Database Monitoring is a crucial aspect of any application deployment. After all, databases manage data and sit quite down in the stack. They are robust pieces of software, but their setup and maintenance need care and attention since any problem has the potential to be disruptive to business.
There is one common performance issue our clients run into when trying their first Cypher queries on a dataset in Neo4j. When writing a query, be sure that it doesn’t match any cycles, or you can experience unpleasant surprises.
When developing web applications with frameworks like Vue.js the best approach is to subdivide it into well-defined and reusable components for the user interface, with the business logic being encapsulated in ‘services’.
Dependencies, like graphs, are everywhere. Achieving a goal is rarely possible in a vacuum and requires collaboration between individuals and/or processes.Eliminating dependencies completely is unrealistic- they are a part of life- but they can be streamlined to improve efficiency and reduce friction.
Few years ago I decided that one day I would create a Graph Technology Landscape map, which would be useful for everyone who wants to discover the players around graph technologies. I started to collect the companies and products, but my research has never manifested into a proper blog post. Till now. I am happy to announce, that the first version of my landscape is published, I hope we can consider this as a start of a long journey.
In this blog we will go over the Full Text Search capabilities available in the latest major release of Neo4j.
Automated testing is the cornerstone of any successful software project.Applications using the Neo4j database are no exception. This blog postshows how to use the Neo4j Dockerimage and the Testcontainerslibrary for integration testing inJava using JUnit.
Do you think there is no space for a graph database in your company? Or it would be a huge effort to integrate a graph database into your product? I have to tell you: You can use a graph database like Neo4j without touching your product, and you can use it for managing your company’s knowledge as well as to improve your software development process. So, even if your business problem is not inherently graphy, there are a few reasons why you should think about your environment as a graph.
IntroductionIn the bucket filling problem you are given two empty buckets, each of a certain capacity, and a large supply of water. By filling, emptying and transferring water between the two buckets, you must try to end up with a situation where one of the buckets contains a required volume of water, or where both buckets together contain the required volume.
The GraphAware Audit Module seamlessly and transparently captures the full audit history who, when, and how a graph was modified.
Enterprise IT requirements are demanding and solutions are expected to be reliable, scalable, and continuously available. Databases accomplish this through clustering, the ability of several instances to connect and conceptually appear and operate as a single unit.
Spring and Spring Boot have become the Swiss Army knife of Java software development, offering dozens of useful modules across a wide range of concerns.One such module is Spring Boot Actuator, a sub-project of Spring Boot, that offers built-in, production-grade functionality to help monitor and interact with an application. Numerous endpoints are included that provide a wealth of information that, among others, include auditing, configuration, environment, and health details.
We are becoming increasingly dependent on technology. Yet, without diligent attention paid to cybersecurity, technology is vulnerable to unauthorized access, change or even destruction. These vulnerabilities pose threats to our individual and collective safety, security and human and economic well-being.Cybersecurity is therefore a vitally important global issue with substantial consequences that depends on safe, stable, and resilient security of our data, devices, and systems.
The success of many enterprises greatly depends on their ability to gather useful information and process it in a timely manner. Automation is essential and so is presentation, giving tangible feedback, to decision makers. This is where technology reaches out to management, where science and design are combined to put the right people in the position of making better and more sustainable choices.
03 Oct 2017
by Alessandro Negro, Vlasta Kůs, Miro Marchi, Christophe Willemsen
· 17 min read
Neo4j
NLP
Companies of any size have to manage and access huge amounts of data providing advanced services for their end-users or to handle their internal processes. The greater part of this data is usually stored in the form of text. Processing and analyzing this huge source of knowledge represents a competitive advantage, but often, even providing simple and effective access to it is a complex task, due to the unstructured nature of the textual data. This blog post will focus on a specific use case: provide effective access to a huge set of documents - later referred as a corpus -...
A book tells us a story, but for a computer it is a wall of text. How can we use graphs and NLP to help our machines make more sense of a story?
“Relevance is the practice of improving search results for users by satisfying their information needs in the context of a particular user experience, while balancing how ranking impacts business’s needs.” [1]
Recommendation engines are a crucial element in the global trend towards a push-based web experience and away from a pull-based one. They provide the ability to personalize content offered to each user by predicting the interest the user will have in the recommended items. This is not only a powerful business tool for content providers, but also a vital improvement to the user experience. In today’s world where the volume, interdependence, variety and speed of information is overwhelming, recommendation engines can significantly reduce the gap between us and what we search for. Indeed, these engines are used even to enhance...
In recent years, the rapid growth of social media communities has created a vast amount of digital documents on the web. Recommending relevant documents to users is a strategic goal for the effectiveness of customer engagement but at the same time is not a trivial problem.
Previous articleshave shown you how easy using Spring with Neo4j can be. Now the next release of Spring Data Neo4j (SDN), we are going to make this even easier!
Whether you realize it or not, the software you create has a global market. Perhaps more so than any other product in any other industry,code that may start as a small, individual effort has the potential to rapidly blossom into a product used around the world.While it is not always obvious that your application can or will have such wide usage, it is in your best interest to maximizethe number of organizations and people you can reach. This means it is important to ensure your software is internationalized and localized.
Without question, Github is the biggest code sharing platform on the planet. With more than 14 millions users and 35 million repositories, the insights you can discover by analyzing the data available through its API are surprising and revealing.
During GraphConnect San Francisco 2015, we introduced the concept of Graph-Aided Search and released the first module providing Neo4j data replication to Elasticsearch.
In the Bersin Predictions for 2016 report, Josh Bersin states that “it feels as though everything in the world of talent is changing – from the way we recruit and attract people, as well as how we reward them, to the way we learn, and how we curate and manage our entire work-life experience”[1].
A great part of the world’s knowledge is stored using text in natural language, but using it in an effective way isstill a major challenge. Natural Language Processing (NLP) techniques provide the basis for harnessing this huge amountof data and converting it into a useful source of knowledge for further processing.
In our previous blog postwe introduced the concept of Graph Aided Search. It refers to a personalised user experience during search where theresults are customised for each user based on information gathered about them (likes, friends, clicks, buying history, etc.).This information is stored in a graph database and processed using machine learning and/or graph analysis algorithms.
As of version 2.1, Neo4j OGM will support persistence events. Although a date for the release of 2.1 isn’t known at thetime of writing, we think this is an important and exciting new feature and so we’ll be writing a series of posts aboutit over the next few weeks to whet your appetites. In this first post we’ll take a quick tour of the new Events mechanismin the OGM, and provide some examples of how we might use it in our own applications. But first, some background…
Spring Data Neo4j 4.1 introduces the ability to map nodes and relationships returned by custom Cypher queries to domain entities. This blog post will explain how different types of query results map to entities.
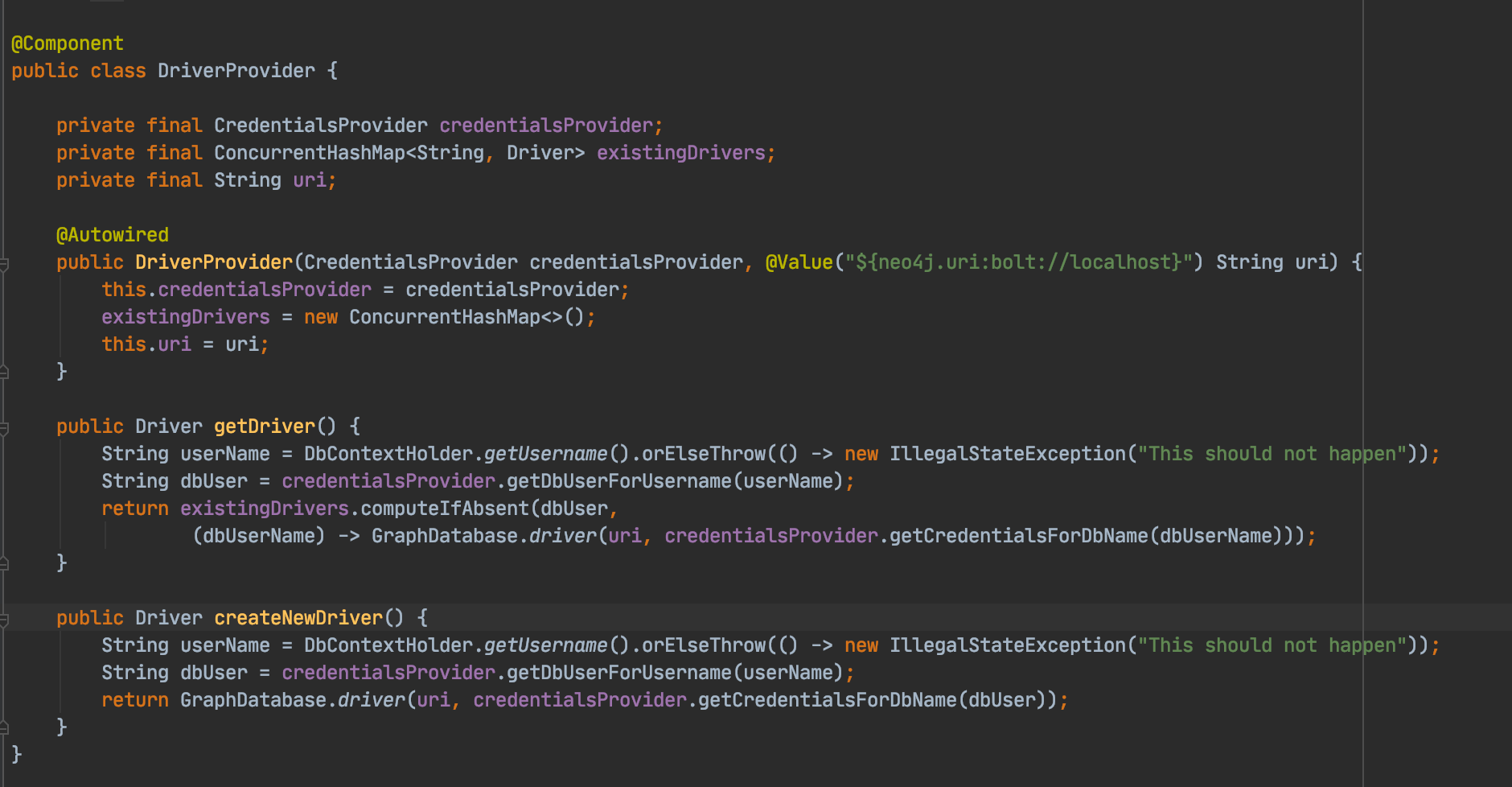
For most organisations, data security is extremely important. The topic comes up every single time we are training, consulting,or otherwise engaging in the world of graphs and Neo4j. At the same time, security is very difficult and time-consuming to get rightand the implications of getting it wrong can be serious. In this blog post, we introduce the integration of Spring Securityinto Neo4j which provides important security controls and mechanisms for enterprises and governments that make use of theworld’s most popular graph database.
At GraphAware, we help organisations in a wide range of verticals solve problems with graphs.Once we come across a requirement or use case two or three different times, we typically create an open-source Neo4j extensionthat addresses it. The latest addition to our product portfolio, introduced in this post, is a simple library that automaticallyexpires data from the Neo4j graph database.
Our previous article demonstrated how easy it was to build an application using Spring Data Neo4j 4.
This guide (first published on Airpair) will get you up and running with Spring Data Neo4j 4 in under an hour.
Iterating over large numbers of nodes using Cypher is quite a common use case in Neo4j. Typically, the reason for doing thisis that we want to perform some kind of operation for each one of these nodes. In this blog post, we will use one millionTestNodes and try to iterate over them in order to index their contents into a freshly created Elasticsearch index.There are three approaches we can take, two of which are quite common, but the most performant technique is largely unknown.
Recently, Neo Technology announced the 2.3.0-RC1 release of their Neo4j graph database. One of the key new features is TriadicSelection built into Cypher’s Cost Based Planner. In this blog post, we will explore the Triadic Selection in detailand demonstrate how significantly it can speed up recommendations computed in Neo4j.
For the last couple of years, Neo4j has been increasingly popular as the technology of choice for people building real-time recommendation engines. Having been at the forefront of the graph movement through clientengagements and open-source software development, we have identified the next step in the natural evolution of graph-based recommendationengines. We call it Graph-Aided Search.
Drawing a graph on a whiteboard is easy and fun! Translating that graph into an object model can sometimes result in questions such as “do I have to define relationships in both participating node entities?”or “which end of the relationship should I save?”.
Writing integration tests for your code that runs against Neo4j is simple enough when using the native API, but there’snot a great deal of help out there if you’re working in client-server mode. Making assertions about the shape of thegraph can also be difficult, particularly if use cases involve more than a few nodes and relationships.
In this blog post, we’ll demonstrate how to use variable length relationships (sometimes called “variable length paths”)in Cypher using examples. We will also see when zero length relationships can be useful.
Over the last few months, GraphAware, Neo4j, and Pivotal engineers have been workingon a ground-up reimplementation of Spring Data Neo4j (SDN) that is server-first and Cypher-centric. Today we are veryexcited to announce the first milestone of the new Spring Data project for Neo4j.
Last weekend, I came across a tweet announcing that Wikimedia released the dataset of the page clickstreamsfor February 2015. I found it interesting to download this dataset and see how people arrive on the Neo4j’s Wikipedia page.
Our earlier blog posttalked about using the Neo4j web browser along with embedded Neo4j.The WrappingNeoServerBootstrapper which was employed to do this has been deprecated for a while and it raises questionsabout the alternative.
A common question when planning and designing your Neo4j Graph Database is how to handle “flagged” entities. This couldinclude users that are active, blog posts that are published, news articles that have been read, etc.
There are times when you have an application using Neo4j in embedded mode but also need to play around with the graphusing the Neo4j web browser. Since the database can be accessed from at most one process at a time, trying to start upthe Neo4j server when your embedded Neo4j application is running won’t work. The WrappingNeoServerBootstrapper,although deprecated, comes to the rescue. Here’s how to set it up.
Specialist in Neo4j consultancy, training, and software development, Graph Aware Ltd has been selected as one of NeoTechnology’s first UK solution partners, under its newly launched partnership program.
In the first part of this short series aboutrandom graph models, we talked about why they are useful and had a brief look at two of them: Erdos-Renyi graphs andBarabasi-Albert model. In this post, we take a look at the “small world” phenomenon and another network model, namelythe Watts-Strogatz model.
With MERGE set to replace CREATE UNIQUEat some time, the behavior of MERGE can sometimes be tricky to understand.
Efficient counting of relationships in Neo4j was the cornerstone of my Master Thesisand the reason the very first GraphAware Frameworkmodule called the Relationship Count Module was born. The improvements in Neo4j 2.1around dense nodes and the addition of getDegree(…) methods on the Node interface made me eager to do some benchmarking around relationship counts again.
When one obtains a graph data from a measurement on a real world network, it is sometimes useful to make comparison witha random graph. Such graph is characterised by certain degree distribution, which you can imagine to be a list of degreesof nodes present in the network. The most interesting distributions have certain functional dependence which allowsone to infer what processes are dominant in formation of the network. The processes consequently characterise therelationships between the nodes.
In the last post of our “Neo4j Modelling for Beginners” series,we looked at bidirectional relationships. In this post, we compare the implications of qualifying relationships byusing different relationship types versus using relationship properties.
Transitioning from the relational world to the beautiful world of graphs requires a shift in thinking about data. Althoughgraphs are often much more intuitive than tables, there are certain mistakes peopletend to make when modelling their data as a graph for the first time. In this article, we look at one common sourceof confusion: bidirectional relationships.
I have just finished a year-long MSc. program in Computing at Imperial College London. My thesis was called GraphAware:Towards Online Analytical Processing in Graph Databases, which you can freely download. It’s not an easy, cover-to-coverread, but there might be some interesting parts, even if you don’t go through all the (over 100) pages.