Knowledge Graphs with Entity Relations: Is Jane Austen employed by Google?
· 7 min read
If you have read our post Hume in Space: Monitoring Satellite Technology Markets with a ML-powered Knowledge Graph, you surely wonder: is there a way to extract relations among named entities without heavy investment? Investment in terms of time to label training dataset and to develop, train and deploy a machine learning model?
Yes, there is! But first things first …
There are many ways to approach the problem. If you are a data scientist, your first instinct is probably Deep Learning (DL). Entity relation extraction, i.e. classifying relation types between named entities such as (:Person)-[:WORKS_FOR]->(:Organization), is clearly a perfect use case for DL as it is a highly complex task with heavy reliance on semantic and contextual understanding of natural language.
There are many model architectures out there that are designed for this task: RNNs, CNNs, GCNs, various Language Models. Some of them are heavier (e.g. Language Models typically have hundreds of millions of parameters and you won’t get far without GPUs), others are lighter (such as LSTMs, trainable even on a laptop), but all of them rely on building a human-labeled training dataset. That typically means weeks to months of tedious human labour. And that in turn means significant costs and project delays - you might find an issue in the dataset and need to reannotate parts of it, or you may need to improve Named Entity Recognition (NER), or fix deployment issues and so on. And NER & ERE are typically not the only models you need: Knowledge Graphs (KGs) construction is a complex task and requires a whole range of functionalities and machine learning capabilities.
We could attempt to bypass this need of human manual work by defining a simple set of regular expression rules. However, this wouldn’t work except for a very few highly specific cases. This is due to the nature of human language - it is rarely highly efficient straight to the point like in this sentence:
"Jane Austen works for Google."
We humans like to tell stories rather than highly condensed facts, so perhaps this is a more realistic sentence:
"Jane Austen, a Victorian era writer, works nowadays for Google."
The distance among key facts (Jane Austen, works for, Google) is rather large. A regex rule for capturing it would have to be too loose as it would have to skip many tokens, meaning it would introduce too many false positives (wrong results).
Let’s turn towards NLP for help. Every NLP library provides a set of basic annotations, such as sentence segmentation, tokenization, stemming, lemmatization, part of speech tagging and dependency parsing. The dependency parsing, specifically, provides a cross-linguistically consistent description of grammatical relations among tokens in a sentence that can easily be understood and used by people without linguistic knowledge. And perhaps not surprisingly, this structure of dependencies and further key information about tokens are easy to store and navigate in the form of a graph. This is how our “Jane Austen”-sentence looks like from such point of view:
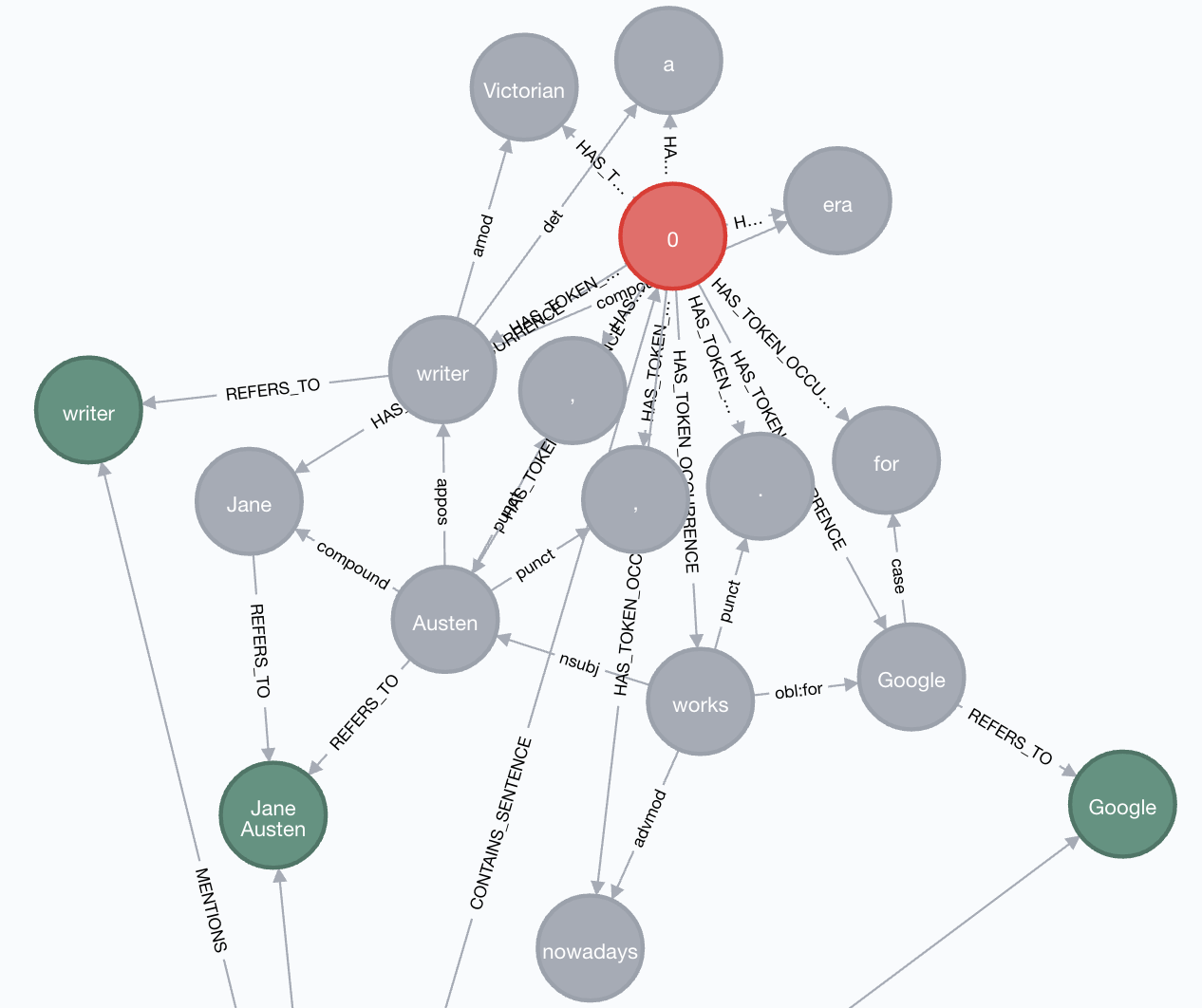
Individual tokens are the grey nodes, all connected to the red node which represents a sentence, and finally green nodes designate merged entities. The grammatical dependencies appear as relationships among token nodes. Despite a fairly complex sentence, we can see that the relationship between Jane Austen and Google is still very straightforward. So straightforward that we can design a simple Cypher query to define a fairly generic rule that will identify WORKS_FOR relation between PERSON and ORGANIZATION named entities in many grammatically similar sentences:
MATCH (s:Sentence)-[:HAS_TOKEN_OCCURRENCE]->(root:TokenOccurrence)
WHERE root.lemma = "work"
WITH s, root
MATCH (e1:TokenOccurrence {ne: ["PERSON"]})<-[r1:DEP]-(root)-[r2:DEP]-> (e2:TokenOccurrence {ne: ["ORGANIZATION"]})
WHERE r1.type = 'nsubj' AND r2.type = 'obl:for'
WITH e1, e2
MATCH (e1)-[:REFERS_TO]->(ef1:Entity)
MATCH (e2)-[:REFERS_TO]->(ef2:Entity)
RETURN ef1.value AS entity1, ef1.ne AS type1, "WORKS_FOR" AS relation, ef2.value AS entity2, ef2.ne AS type2
Similarly, we can define a HAS_TITLE rule - it is actually even simpler than in case of WORKS_FOR, because the TITLE (writer) is connected to PERSON (Jane Austen) directly through appos dependency (“appositional modifier”).
To summarize, what we need is:
- a document ingestion pipeline
- an NLP tool with dependency parsing
- an NER model for recognizing the key entities in the text
- a proper graph model to store the hidden structures extracted from the text in an easy to query data structure
- a graph database for persisting the dependency relationships as an intermediate step
- a set of Cypher rules for extracting entity relations
- another graph database for storing the inferred KG (we use Neo4j and its multi-database feature; this way we keep separate the relevant knowledge in one DB as a Knowledge Graph and all detailed metadata in another - helper - DB)
- the visualisation on top of the KG to deliver extracted insights to the end user
All this (and much more) is facilitated by Hume, GraphAware’s graph-powered insights engine. The next examples show how to use it for building a knowledge graph out of multiple news paper RSS feeds. The ingestion workflow below (which leverages Hume.Orchestra, the data science workflow engine available in Hume) pulls data in regular intervals RSS feeds from specified sources (Fortune, ESA Top News, BBC Business etc.), runs basic cleansing, stores Document nodes to Neo4j and sends the feeds to RabbitMQ writer.
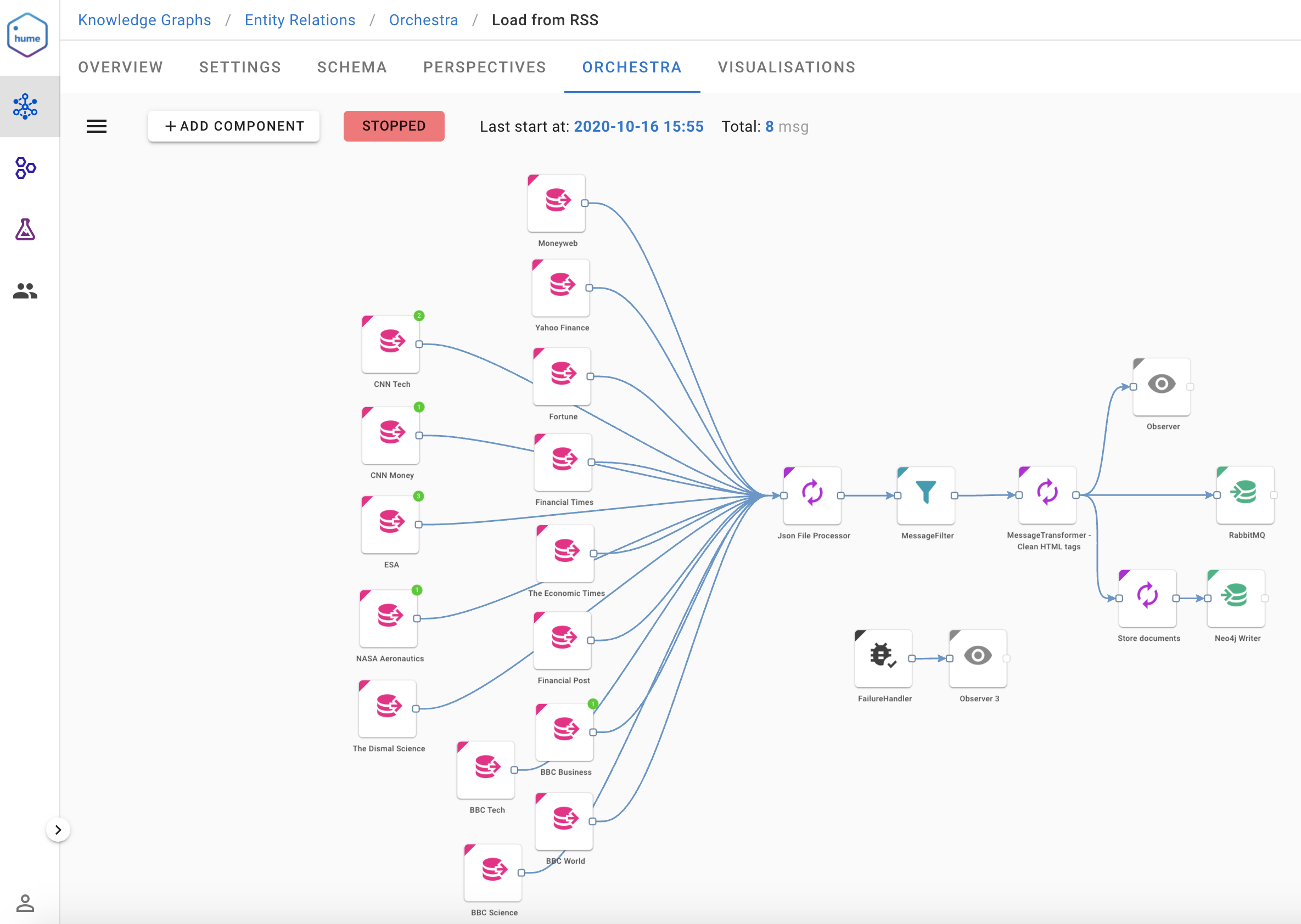
The subsequent workflow consumes messages from RabbitMQ and sends them to several dedicated components:
- Entity Extraction - runs NLP with NER
- Token Occurrence Neo4j Writer - writes token dependency graph into Neo4j helper (metadata) DB
- Rule Based Relation Extraction - extracts relations based on provided rules in JSON format (see below for details)
- Keyword Extraction - runs keyword & keyphrase extraction algorithm
- Neo4j Writer - store all results to the KG
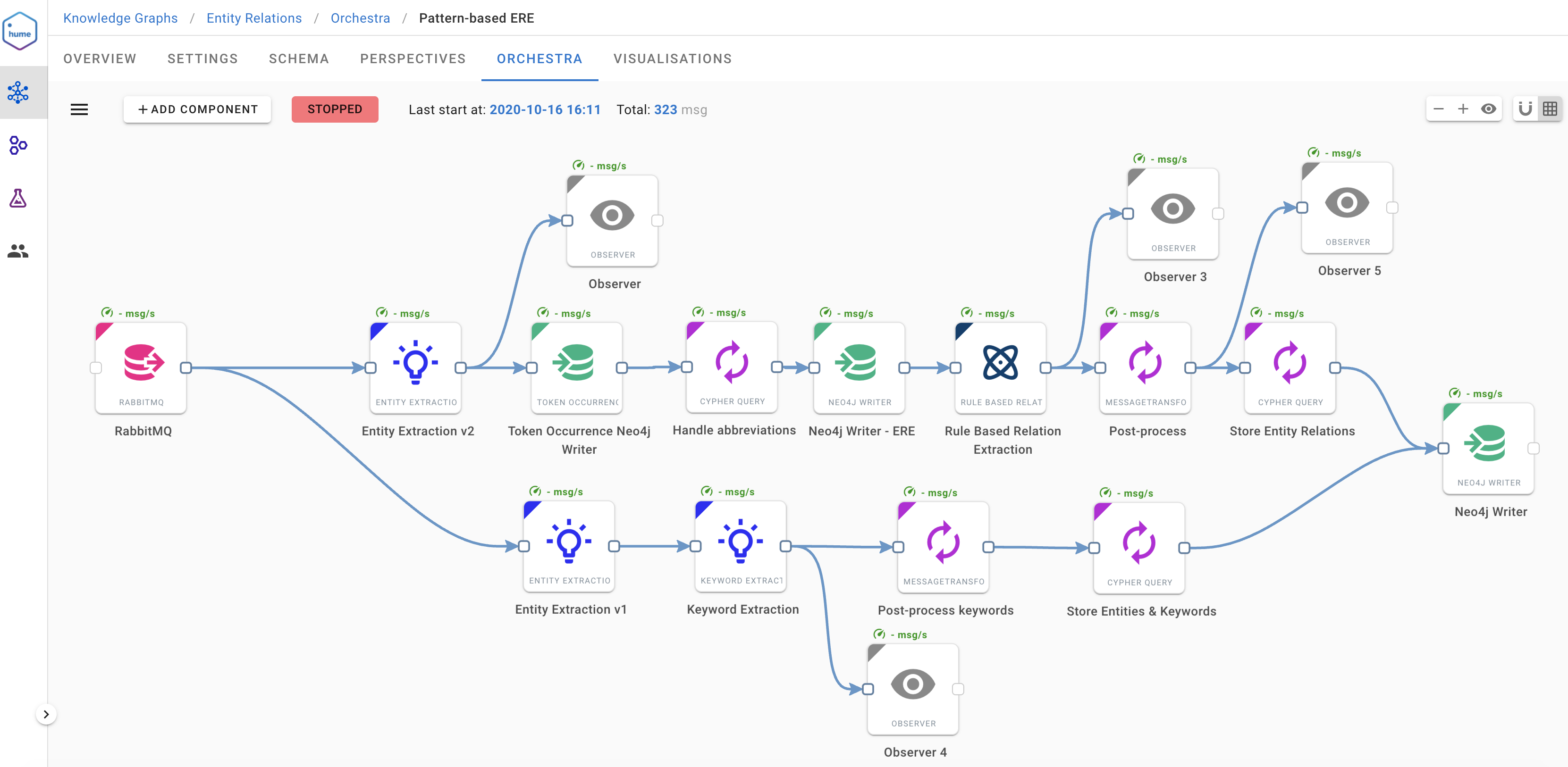
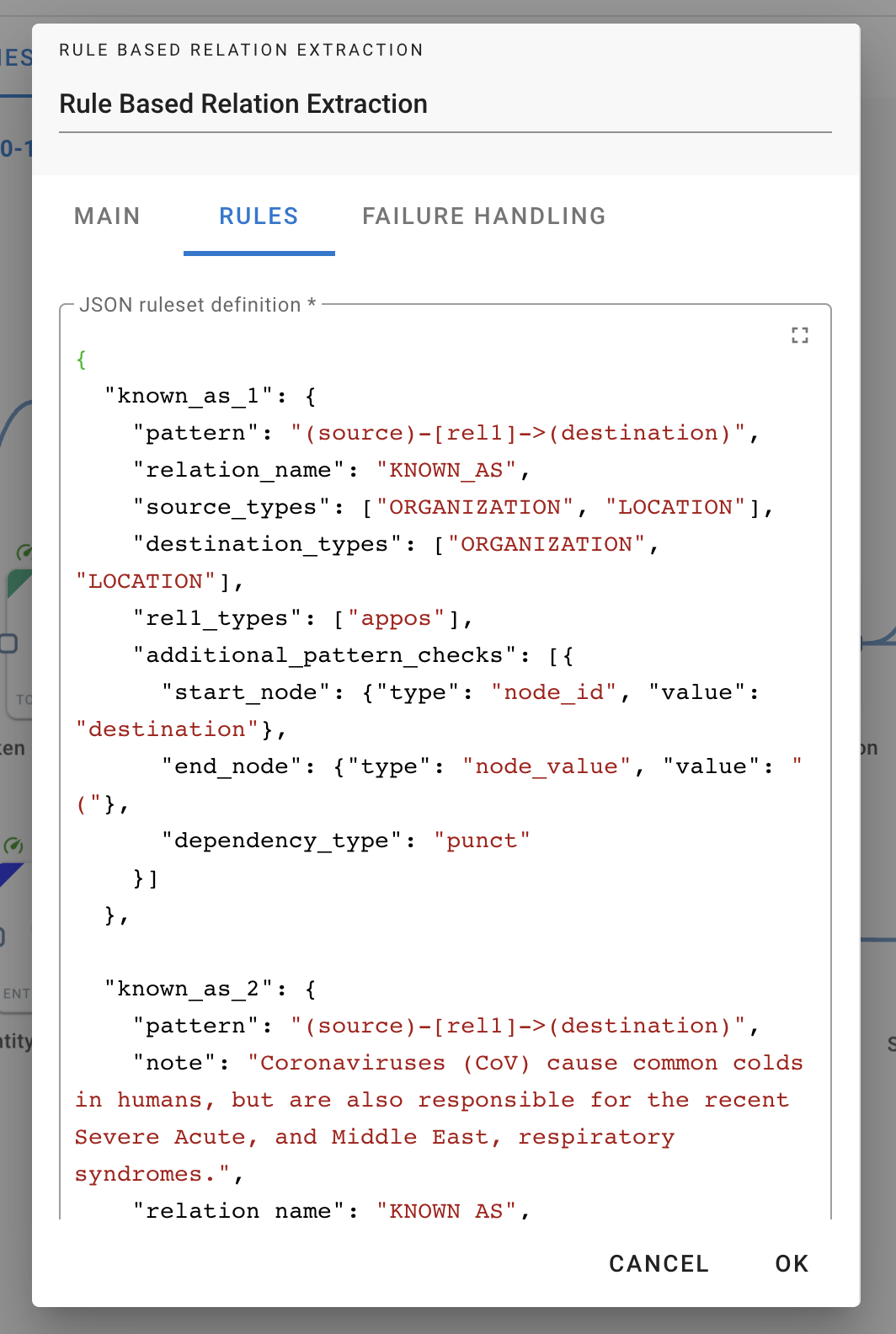
In our implementation of Rule Based Relation Extraction component, we decided to further simplify the rules and defined a JSON-style configuration of the ERE patterns. One just provides a list of JSON objects (multiple rules) and the translation into relevant Cypher queries is done internally. This makes the use of this approach easier for everyone, even for those who are not strong in Cypher.
The resulting graph schema we use in this exercise contains documents, keywords, various named entities and relations among them:
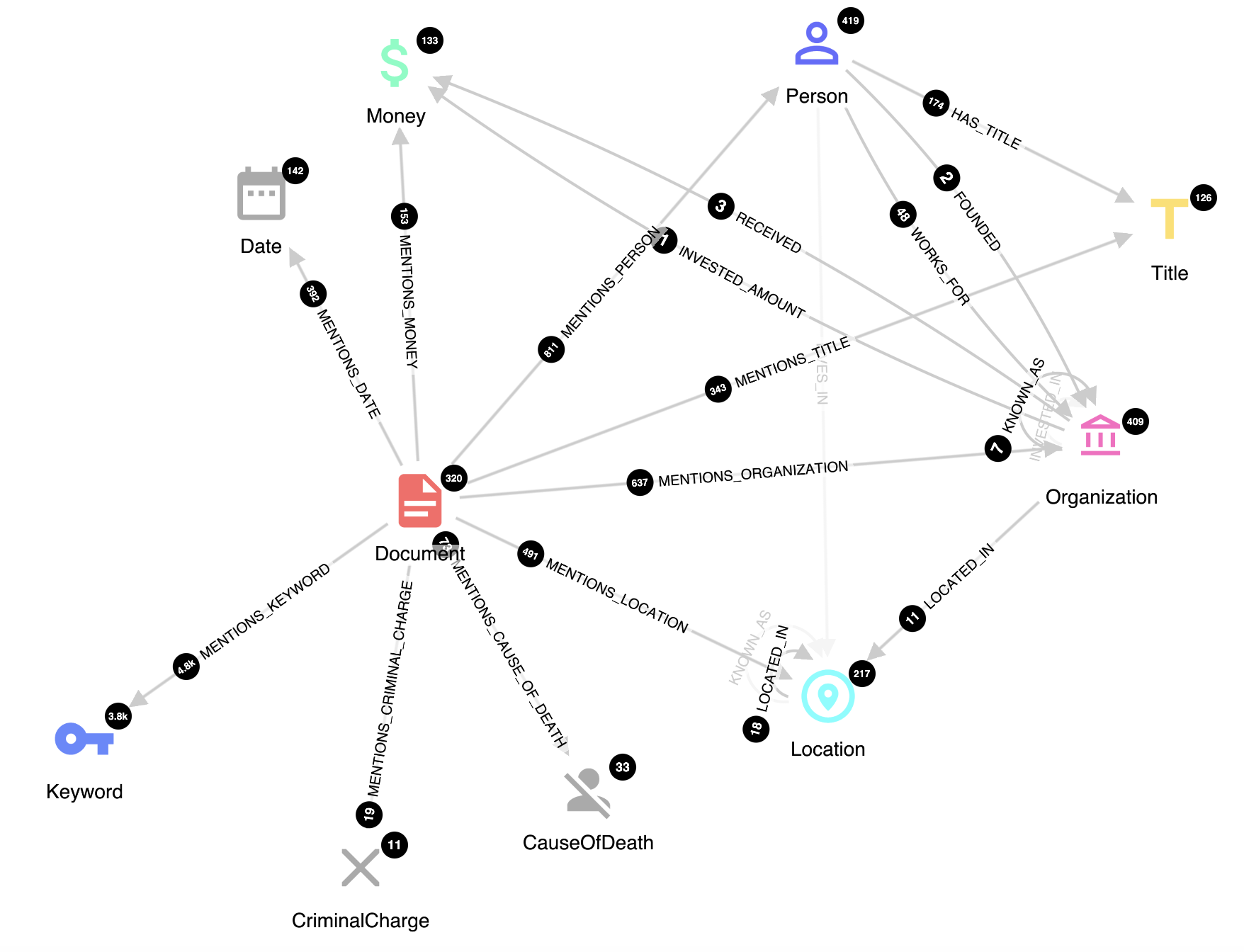
This way, we can create a custom knowledge base directly from our own data, instead of relying on human-curated knowledge, which moreover needs to be kept updated according to how our domain evolves over time. This is an example of knowledge we obtained from couple of RSS feeds using the methods described above:
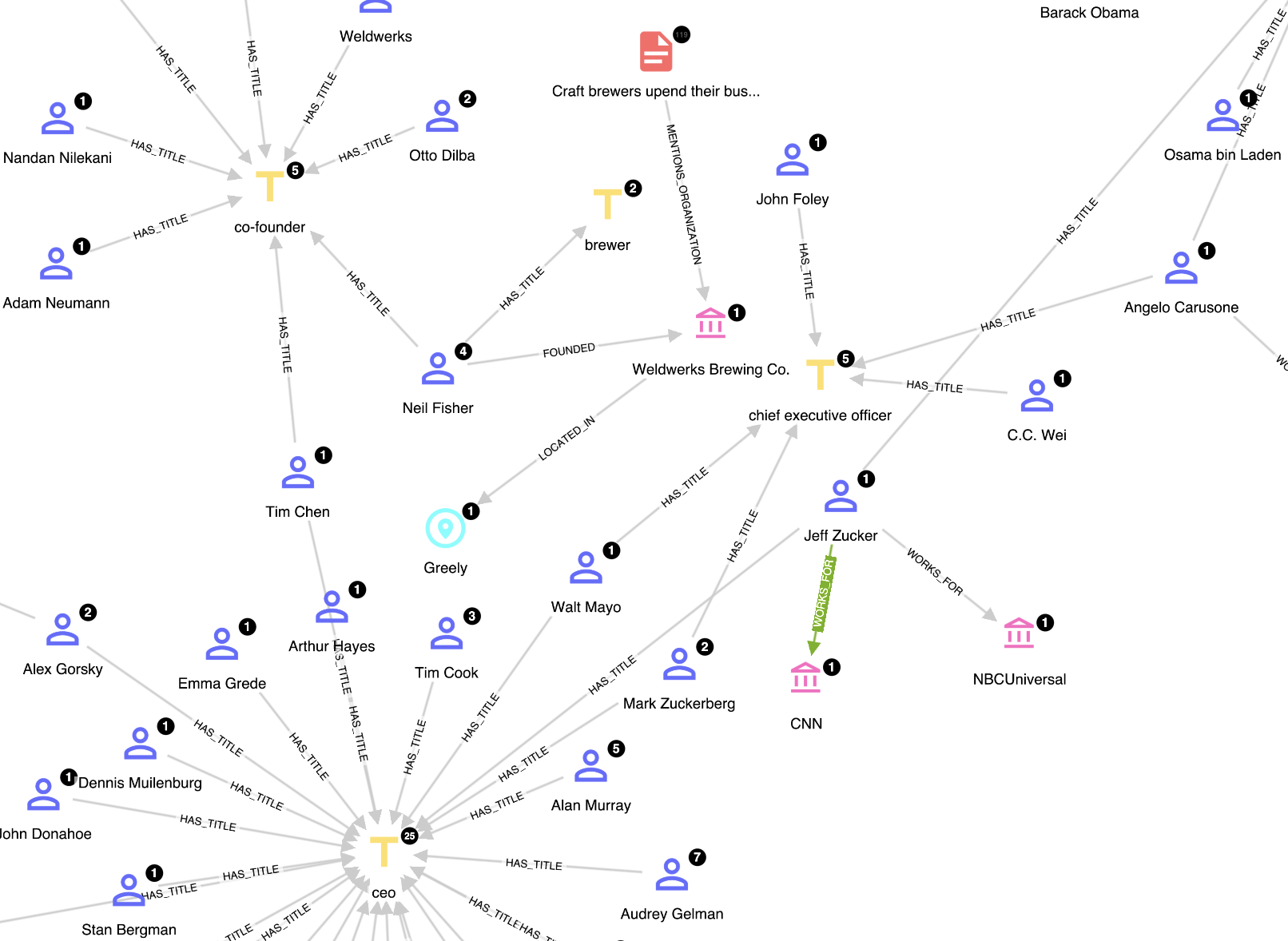
Our system identified lots of CEOs, founders, co-founders, their business titles and organizations they work for, such as Neil Fisher being a co-founder and brewer at Weldwerks Brewing Co. Or as in case of the ESA use case mentioned at the beginning of this post, where we trained an ERE model (a graph convolutional network) for linking companies and their investment in the space industry. The possibilities are endless.
Designing and fine-tuning a system based on a combination of dependency parsing and rules through Cypher queries is significantly easier than building a ML model, but it is still a non-trivial task even with a product like Hume, especially when you need to scale such a pipeline. Plus just like in case of any ML model, it is never 100% precise. One has to carefully design the rules in such a way that they are not too strict (otherwise they wouldn’t pick much more than the specific sentences they were tested on), but not too loose either (many false positives). This work is however worth the effort. Not only are you able to quickly demonstrate a concept and produce a minimal viable product, but you can also leverage such a tool in the next phase - to produce a semi-supervised training dataset for a ML model.
At GraphAware, we have gone through the process of building a Knowledge Graph from structured and unstructured data alike for various customers from different industries many times. Get in touch, we are happy to assist you as well!