Hume in Space: Monitoring Satellite Technology Markets with a ML-powered Knowledge Graph
· 10 min read
Everyone has a passion for something. Be it music, politics, sports, coffee or … pancakes. Such passion makes you strive for new information, for understanding of the current trends. Take pancakes: you might watch for new recipes on your favourite website, you might look at cooking shows or youtube videos to get more inspiration about how to serve them … but overall, you can probably handle this pretty well. It’s not like there is much room for revolutionising the pancake recipe.
Imagine a different context: let’s say that your passion is not limited to your kitchen, but reaches from the ground to tens of thousands kilometres up (yes, way beyond the reach of Earth’s atmosphere), and of course transcends also continents. Imagine you’re the European Space Agency (ESA).

The space industry is not what it used to be. This decade has seen a sharp rise in the number of private companies entering the space - literally as well as figuratively (through investments, supplying hardware and other technologies). And it is global. Companies from all over the world are involved. Space Angels estimates that there are around 400 private companies in the space industry with $19 billion in private funding - just since 2009! There are well known big players and front runners such as Airbus Defence & Space or SpaceX, but also many disruptive startups (for example Isar Aerospace developing orbital launch vehicles for small and medium satellites). In this vibrant and constantly changing ecosystem, it is simply not possible to rely on individuals reading (and reporting) all the news about companies building space technologies, satellites, rockets etc., or about investments into such companies. And the amount of public data about this market is steeply increasing. The new space race for the Moon and beyond (Mars, here we come!) is just starting and companies and investors sense new business opportunities …
In terms of data scouting and processing, the challenge of monitoring the satellite technology market is similar to the famous Panama Papers - getting access to the vast amount of unstructured data is just a first step on the journey of discovery …
To the Orbit and Back: Satellite Technologies
Satellites are highly complex devices consisting of multiple interconnected technology sub-systems, components and functionalities. Typically, a very wide range of institutes, universities and private companies are involved in the effort to launch a new satellite to orbit. ESA’s ambition is nothing less than to map this highly complex interconnected and constantly evolving ecosystem into a single easily navigable knowledge base. This goal is not achievable by using only “human power”, given the abundance of the data sources. The only way to deal with it is to use an automated Machine Learning approach. ESA decided to learn more about the Natural Language Processing (NLP) and a graph-powered insights engine capabilities through a proof of concept activity with GraphAware.
To illustrate the complexities, take this SpaceNews article about new funding for OneWeb company.
WASHINGTON — Less than a month after the launch of its first six satellites, OneWeb closed a new $1.25 billion financing round to further its internet constellation. Japanese tech giant SoftBank — OneWeb’s largest investor — led the round, as did returning investors Grupo Salinas, Qualcomm Technologies, and the government of Rwanda. The new financing brings OneWeb’s total funding to $3.4 billion, following a $500 million round in 2015, a $1.2 billion round in 2016 and undisclosed fundraising of around $450 million last year.

It starts to be clear that in order to extract relevant knowledge, we need not only to recognize entities in the text, such as “OneWeb”=COMPANY and “$1.25 billion”=MONEY, but also the ability to relate these entities. Machine Learning models can be trained to turn unstructured data into highly structured insights: company OneWeb received $1.25 billion from SoftBank.
And there are many more entities and relations among them that could be of interest. Basically, the whole complex dependency chain, such as which companies partner with whom to build what, can be modelled by ML algorithms aiming to get the most from public data sources.
Grasp the Knowledge
From the Machine Learning point of view, extracting such types of information requires two main activities:
- Named Entity Recognition (NER)
- Entity Relations Extraction (ERE)
NER is focused on identifying domain specific entities in the text, such as COMPANY, SATELLITE, or MONEY. Then ERE is used to classify relations among these entities, such as INVESTED, RECEIVED and many others. Final ingredient is a graph database - about that further down this post.
As for the data, think of scraping online news articles, RSS feeds, blog posts, PDF documents, CSVs and so on. Any combination of public data sources is exploited to build a domain specific knowledge base by the use of state-of-the-art Machine Learning models. And all this - data ingestion, processing, enrichment and storage - is managed by GraphAware’s flagship product: Hume, a graph-powered insights engine.
Named Entity Recognition
Named Entity Recognition (NER), also known as entity extraction, is a task of identifying named entity mentions in unstructured texts and classifying them into predefined categories. There are various techniques ranging from simple rule-based NER methods that use dictionaries and regular expression rules to machine learning approaches such as Conditional Random Fields (CRFs) or Recurrent Neural Networks. Finally, recent years brought transfer learning to the NLP domain and we can thus use even pre-trained models such as BERT for sequence classification.
Choosing the right model for a specific use case is not a simple task. We are flooded almost daily with new research papers or blog posts claiming that they have the current best model, however when one looks at the literature with a proper scientific evaluation approach, it becomes quickly apparent that even methods which have been around for a while, such as the CRFs, are still among the top performing models, see for example this paper. Latest language models can indeed outperform simpler approaches, but often just by few percent. It’s not unusual to see bold celebrations of reaching state of the art performance, but when you look at numbers, the improvement is often in the range of 1-2%. We leave it up to our kind readers to decide whether barely a few percent gain in precision and recall is worth having to deploy not just model training, but also models for predictions on expensive GPUs, vs. the ability to train & predict right on your laptop models such as LSTMs or CRFs.
Given the above, our default go-to solution for NER are CRFs, though we are able to use other approaches when deemed necessary.
Entity Relations Extraction
Entity Relations extraction is the task of autonomous identification of semantic relationships among two or more entities. There are several ways of extracting such relations and they vary from hand-built extraction rules to advanced machine learning methods based on deep neural networks or even language models such as BERT. Hume provides two different implementations in its ecosystem to train the entity relations models: Long Short-Term Memory (LSTM) Neural Networks and Attention Guided Graph Convolutional Networks (AGGCN). For the specific needs at ESA, and after extensive tests, we decided to use the AGGCN model as we found that it tends to outperform the LSTMs.
The most interesting difference of the AGGCN approach to the LSTM one is that it uses dependency trees as a source of information for relationship extraction. In particular, it takes a full dependency tree as an input, performs soft-pruning which learns to attend to the relevant sub-structures and uses them to discover patterns needed for classification of relationships between entities. The model architecture is outlined in the figure below.

There are three main components:
- Attention Guided Layer (bottom left): dependency tree is transformed into attention guided adjacency matrices (fully connected edge-weighted graphs)
- Densely Connected Layer (top left): generate new representations from adjacency matrices in multiple sub-layers
- Linear Combination Layer: combine outputs of Densely Connected layers
Bringing in the Domain Expert Knowledge
Since a key part of every supervised ML model is obtaining training datasets, part of the Hume insights engine is Hume Labs: an annotation tool optimised for easy and fast NER & ERE data labelling by a team of domain experts acting as annotators. This way, ESA created datasets that were used to build models, which then became part of the processing pipeline of the final product. Despite having the right tool, obtaining a dataset of sufficient size and quality is a long process. That’s why we work with our clients iteratively: certain amount of data gets annotated, we analyse it, train models, evaluate the quality and provide feedback to the annotators with overview of annotation issues (such as missed or wrong labels) and recommendations for annotation style. This process is repeated multiple times until satisfactory model quality is achieved.

Results
The quality of ML models depends not just on the size and quality of the dataset, but also on the definition of the classes: we have seen cases when even humans without more global domain-specific knowledge would struggle to correctly classify entities or relations among them. That’s why GraphAware, besides supplying Hume, provides also support in the form of consultancy: we work with the customers iteratively throughout the project, constantly monitoring the quality of the data and resulting models. Moreover, in this way we can identify potential fundamental issues early and adjust the annotation style or even the schema itself.
Thanks to the close iterative collaboration with the domain experts, we were able to reach 90-95% F1 score for several important Named Entity types, others not lagging behind more than 5%.
The Entity Relation Extraction is a more challenging task compared to NER. Various research papers in this topic also manifest a notable class variance - some relation types can easily reach 95% F1, others in the literature barely touch 70%. We observed similar behaviour. For several classes, we surpassed 90% F1 score. Others performed worse, averaging in overall around 80%.
Considering that these are results from a relatively short Proof of Concept project, we consider the performance of both NER and ERE models as a success. Our future aim is to further improve by increasing the dataset quality and its size, together with further improvements in the algorithms.
Graphs and Knowledge: Partners for Life
Now we have NER and ERE models which structured information such as:
(OneWeb)-[:RECEIVED]->($1.25 billion)
(SoftBank)-[:INVESTS]->(OneWeb)
We can deploy these models for example on any new articles from space-related RSS feeds. The question now is: how do we turn this information into valuable easy-to-navigate insights?
The answer is: via a Knowledge Graph.
Knowledge Graphs (KGs) are what makes all the difference between outputs from the data science team and the actual value for the business.
In this project, we used GraphAware’s Hume, a graph-powered insights engine. The Hume ecosystem provides a full end-to-end solution for automatic KG building and analysis: from data ingestion, transformation and ML processing to the final result - the graphical representation of the knowledge, which makes it a natural tool for interpreting, sharing with others and using as an intelligence platform.
The process was as follows:
- Hume Labs: ESA team annotated training corpus for NER & ERE models
- Hume Orchestra configuration
- Knowledge Graph visualisation

Hume Orchestra - the workflow management system - was configured to ingest various unstructured data (PDFs, CSVs, RSS feeds …), process it with custom trained Named Entity Recognition and Entity Relations Extraction models and post-process the results such as materialising the named entities and relations among them to the graph in alignment with the domain schema. The screenshot above is an example of a pipeline for ingestion of RSS feeds.
Finally, the Knowledge Graph visualisation, built on top of the Keylines toolkit, was used to demonstrate the ease of providing custom insights through Hume Actions - graph operations defined in the Hume UI through Cypher queries. See a sample screenshot below.
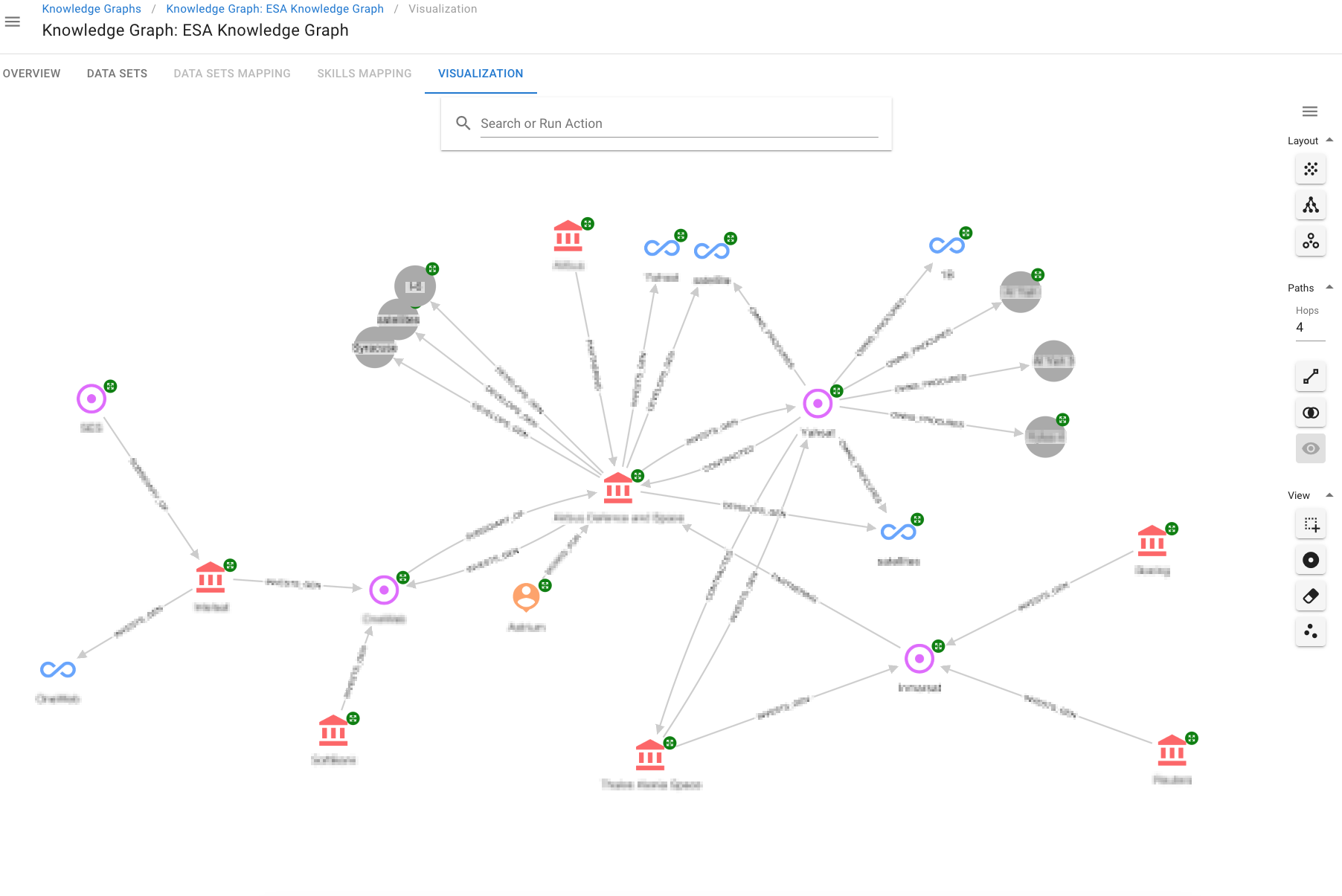
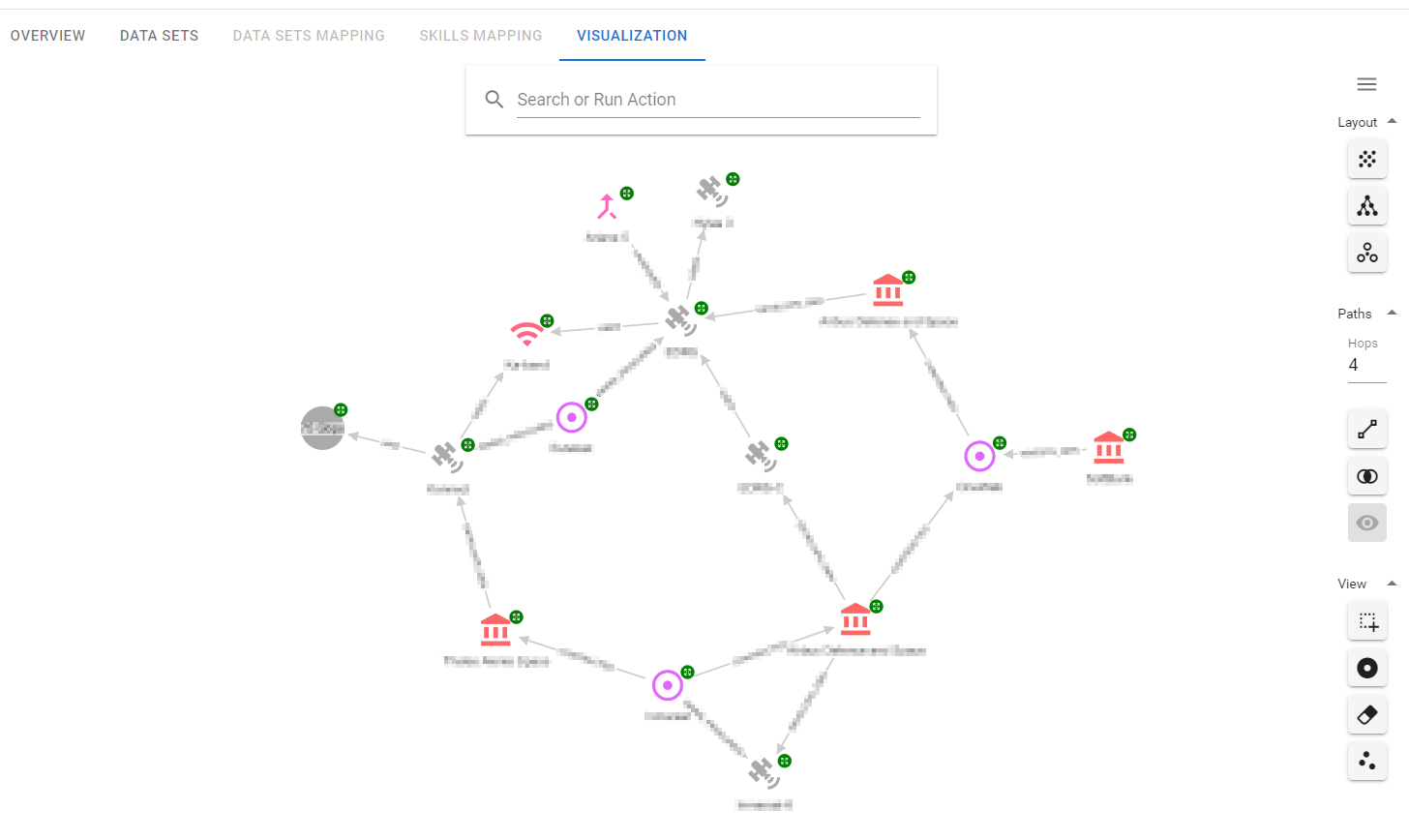
Conclusions
The European Space Agency had a challenge: their small-scale internal exercise clearly demonstrated value in monitoring and analysing the satellite technology market by leveraging the benefits of Neo4j graph database. However, the amount of available unstructured data would require so much human effort that it made it impossible to proceed further. They engaged us for a proof of concept for our graph & NLP capabilities and together we configured an end-to-end solution based on Hume for mapping a segment of the satellite market ecosystem into a Knowledge Graph, accessible through the easily customisable visualisation. ESA is now preparing to build on this successful initial demonstration and drive more usage through the organisation in order to help it best focus its support efforts.