Neo4j 4.0 has just been released with a key feature: graph and sub-graph access control. Access to certain labels or relationship types or properties can now be handled at the database level, resulting in developers not having to deal with complex security logic in their code, and also providing a more consistent and performant solution.
It’s been a year since I published the Graph Technology Landscape 2019 post on GraphAware’s blog. I consider this a success story because it got a lot of attention and publicity. The landscape was mentioned many times at different places; it was used by Emil Eifrem in his GraphTour and GraphConnect opening keynotes, it was displayed in conference halls, and I received many, many useful comments and feedback. I was even invited to Rik van Bruggen Graphistania Podcast to talk about it, and the episode was referred to in the Top 5 Neo4j Podcasts of 2019 blog posts as well....
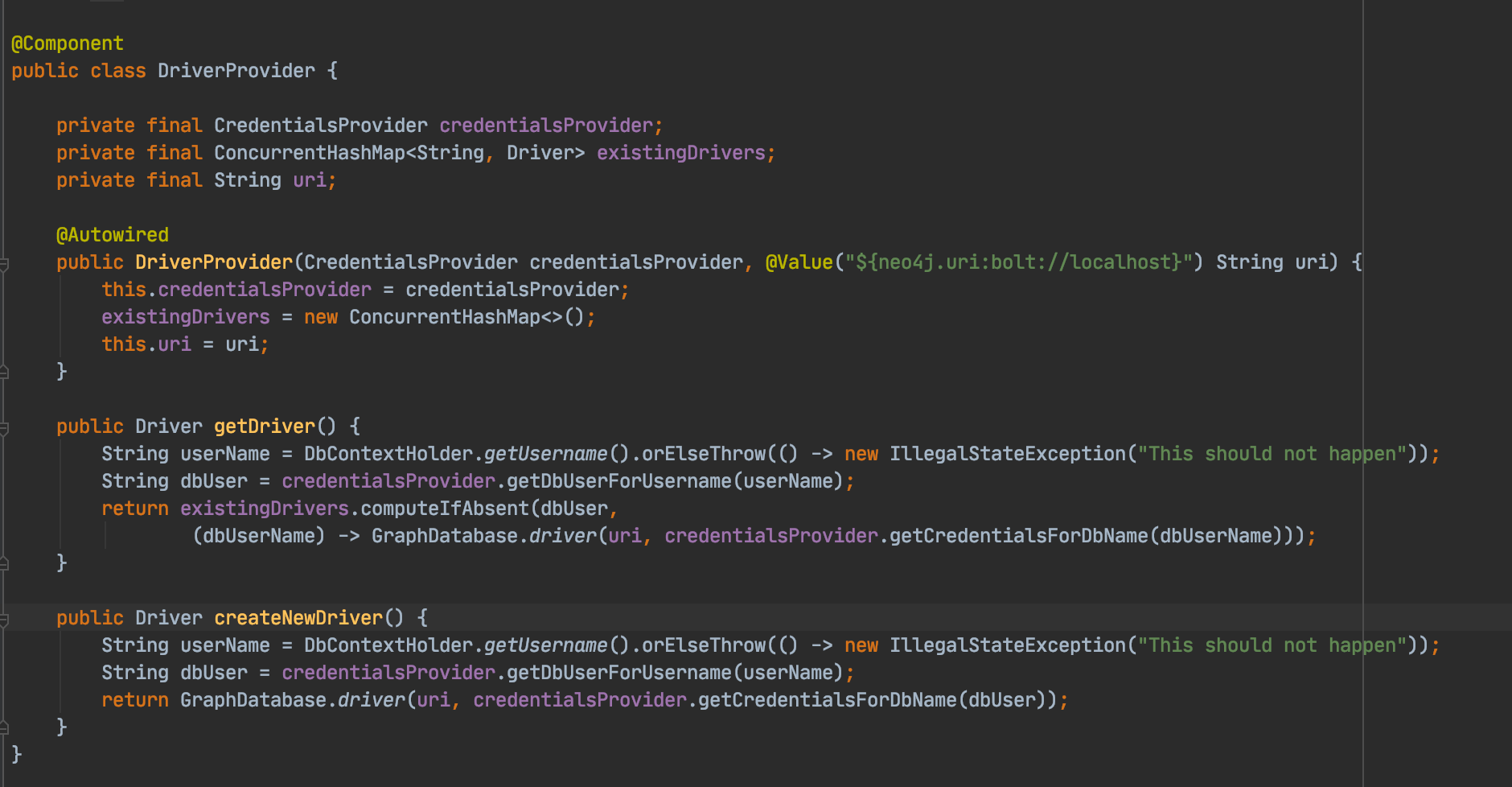
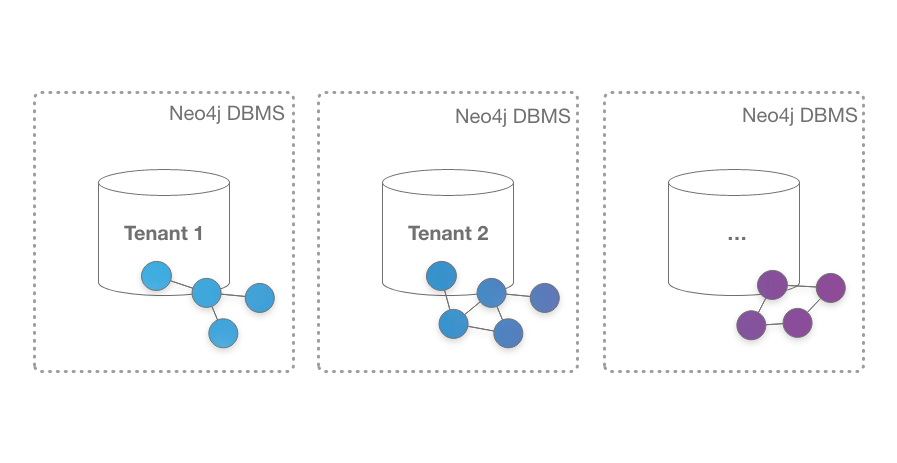
Up until version 4.0, Neo4j has supported only one active database per server instance. As such, achieving multi tenancy meant that either a Neo4j instance had to be deployed per tenant, or all tenant graphs co-existed in the same database.
Many, many years ago, I requested for the Cypher UNION clause in Cypher and Andres Taylor graciously added it.This was followed by the request for Post-Union Processing by Aseem Kishore, and it began to collect a whopping 99 comments over the course of time.
So you have followed the Deep Dive into Neo4j’s Full Text Search tutorial, learned even how to create custom analyzers and finally watched the Full Text Search tips and tricks talk at the Nodes19 online conference?
GRANDstack tips and tricksUsing GRANDstack can rapidly accelerate the development of applications. The neo4j-graphql-js library provides the ability to translate GraphQL queries from the frontend to Cypher queries. This is achieved by defining the GraphQL schema and annotating it with a few extra directives. If you want to get familiar with the GRANDstack you can visit their documentation.
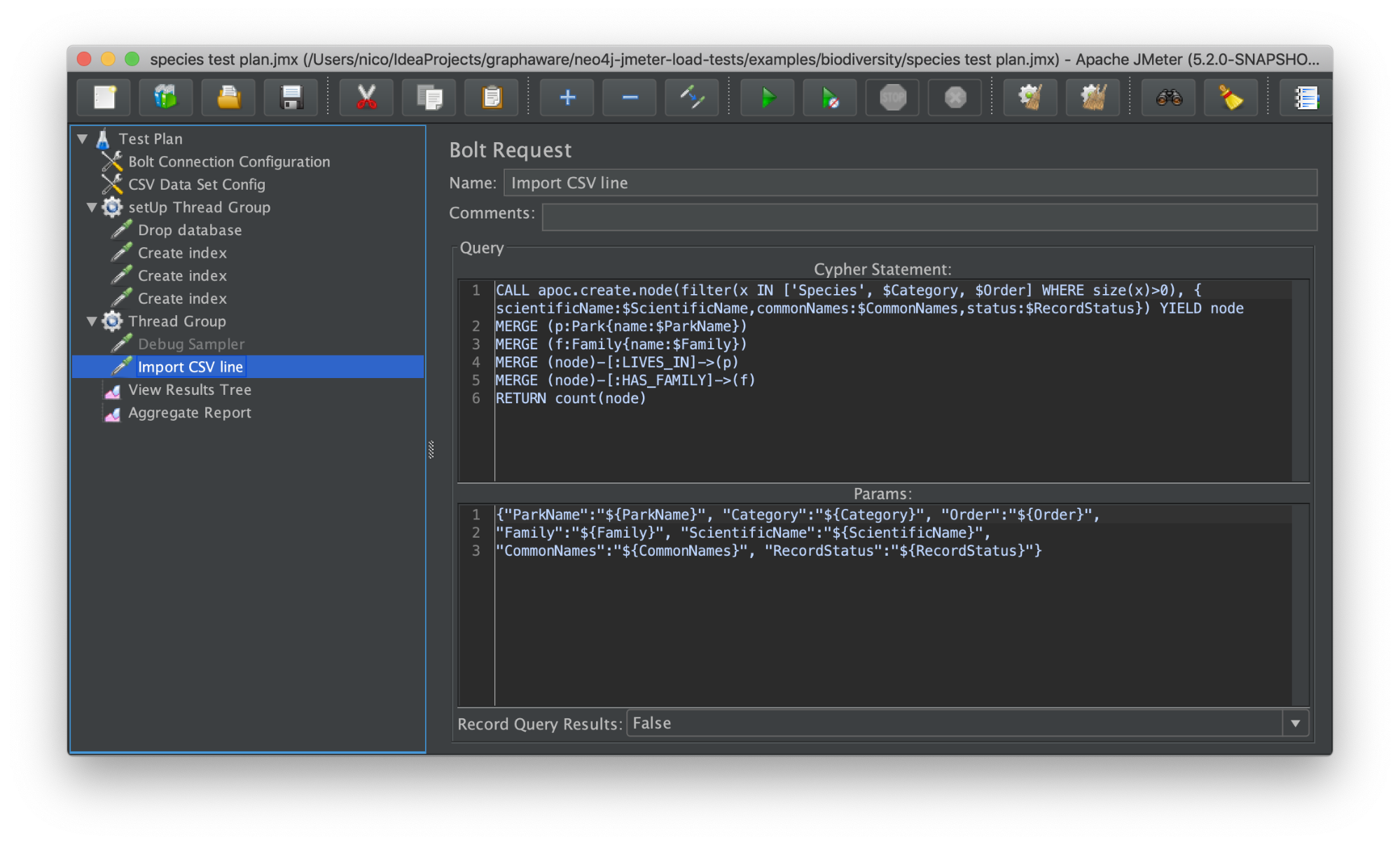
For the Global GraphHack 2019, we extended JMeter to support the Bolt protocol and do load testing on Cypher queries.
BANGALORE, October 10, 2019 – Softlink Information Systems and GraphAware are pleased to announce that they have entered into a global strategic partnership, combining Softlink’s industry leading database consulting services with GraphAware, the leading Neo4j ISV and consulting practice, and the creators of Hume, a cutting-edge Graph-Powered Insights Engine.With knowledge graphs playing an increasingly critical role for enterprises to move to the next level of information analytics, companies recognize that they need to accelerate the development of knowledge graphs to ensure they remain on the competitive vanguard. The Softlink-GraphAware partnership brings together deep skills in business and technology strategy, driven...
We have already blogged about fulltext search available in Neo4j 3.5. The list of available analyzers covers many languages and fits various use cases. However once you expose the search to real users they will start pointing out edge cases and complain about the search not being google-like.
Do you use D3 for data visualisation and either you are considering, or already using it also for graph visualisation? Keep in mind that D3 uses SVG for rendering. While it is the easiest to work with API for drawing 2D graphics on the Web, its downside is that the browser keeps the entire DOM tree of vector elements in memory, even for elements that are effectively invisible. You might hit a performance drop with complex graphics, specifically for graph visualisation when you try drawing graphs larger than ~1000 nodes, or even less with complex SVG effects.